Web Scraping and Named Entity Recognition
Web Scraping and Named Entity Recognition
What you’ll learn
-
What is web scraping and why you might need it?
-
Web scraping using Python and BeautifulSoup
-
Text Mining and Name Entity Recognition
-
Using Stanford Named Entity Recognizer (NER) program to extract name entities from text.
Introduction
In most cases we rely on databases, APIs, or CSV files to source data for a data science project or assignment. However, sometimes the data you require might not be easily available through a database or an API. In such circumstances you’ll be forced to think of other ways of getting that data. Usually the data you are looking for is on a webpage in a form of an HTML document. This is when web scraping might be just what you need to do.
Web Crawling
Web scraping (also termed web crawling or web data harvesting) is the process of extracting and parsing data from a website. This process is usually automated so that huge amount data is extracted from multiple websites and stored into format you can work with in your data analysis. The numerous techniques that data scientist use to perform web scraping range from python libraries such as Request and BeatifulSoup to web crawling frameworks such as python Scrapy.
In this article we’ll focus on using Python’s very powerful library called BeautfulSoup to extract data from a web page. For illustration purposes we will used a simple HTML file which is a part of a story from Alice in Wonderland.
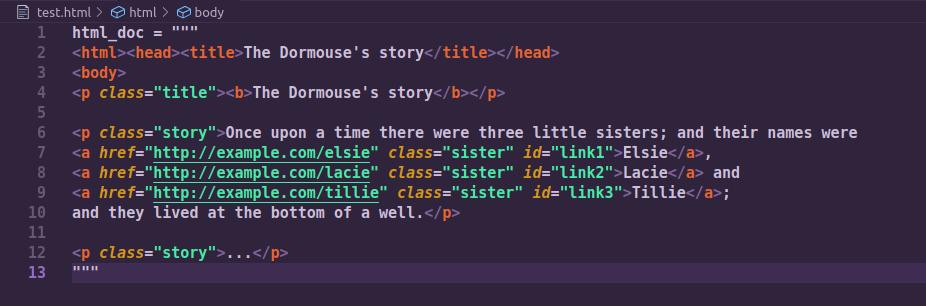
Running the above HTML document through Beautiful Soup gives us a BeautifulSoup object, which represents the document as a nested data structure:
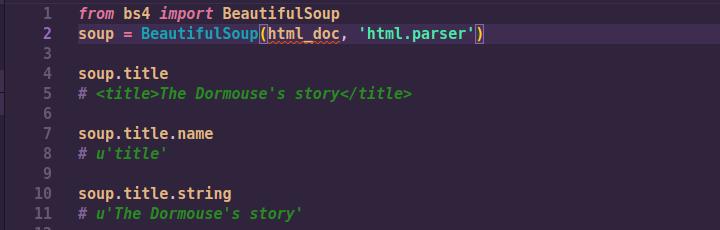
As illustrated in the above lines of code, the attributes of the html document can be easily accessed from the BeautifulSoup object. Furthermore, you can do more advanced queries such a finding all the ‘a’ tags in the HTML document, or finding a specific attribute through its ‘id’.
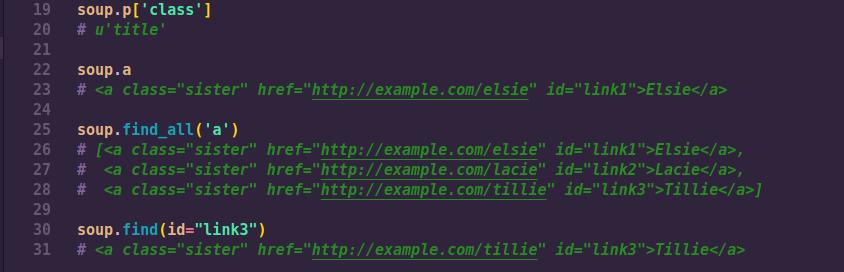
In most cases when doing web scraping, you might want to get all the URLs found on a web page. This is useful when you are dealing with news site, like Yahoo, that show news articles from other sources.
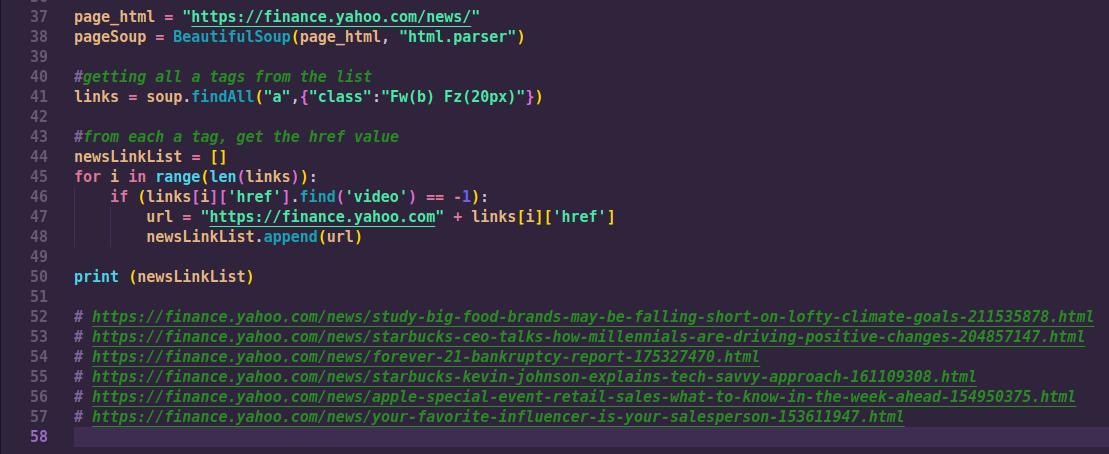
Once we have the URL links of every article in the yahoo news homepage, we can then repeat the same process for each link and transform the news webpage page into a BeautifulSoup objects and access any HTML attribute we want from that page. In a single news article webpage, we can scrap the author, time of article publication, title and content of the article.
Name Entity Recognition with Stanford Named Entity Recognizer (NER)
Text mining, which is sometimes referred as text data mining or text analytics, is the process of deriving high quality information from a corpus of text. Text mining helps data scientist makes sense of the text data, identify patterns and extract valuable information and new knowledge.Named entity recognition (NER) is usually first step towards information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages.
In this article we will introduce the Stanford Named Entity Recognizer (NER). Stanford NER is a Java implementation of a Named Entity Recognizer. The Stanford NER has three models. The 7class model which will give seven different output named entities like Location, Person, Organization, Money, Percent, Date, Time.
You can also use —
-
english.all.3class.distsim.crf.ser.gz: Location, Person and Organization.
-
english.conll.4class.distsim.crf.ser.gz: Location, Person, Organization and Misc.
To use Stanford NER library, you need to;
-
Install NLTK library - pip install nltk
-
Download Stanford NER library from https://nlp.stanford.edu/software/CRF-NER.html#Download. You need store the downloaded file on your python working directory so that you can just use the relative path to access it.
Now let's demonstrate;
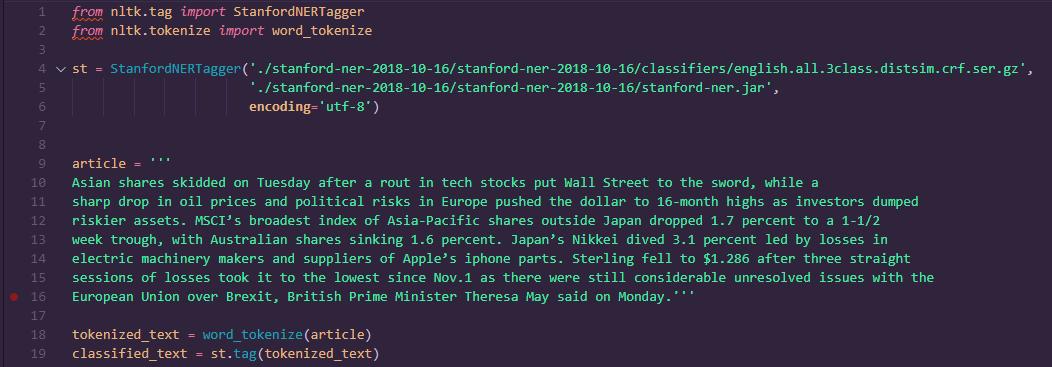
As shown in the picture, we have a text from a news article which we would like to analyse and find out some name entities.
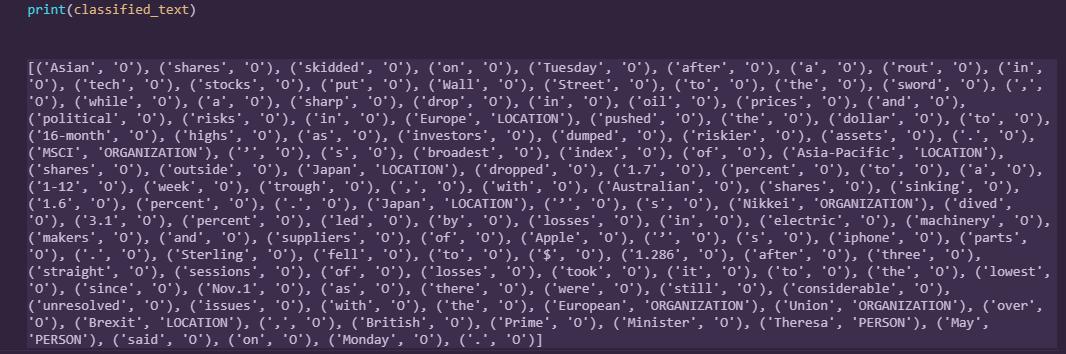
If we output the result after running Stanford NER, we get a dictionary of all the words from the article tagged with name entities. Note that “O” is something which is not tagged or can be called as “Others”.
Practical Application of Web Scraping and NER
Challenge;
-
Get stock news articles from yahoo news website by web scraping the article using BeautifulSoup. We can also extract additional information such as publish time, author, title and obviously, the news text
-
In each article, find out which companies have been mentioned using Stanford NER
-
Identify if the a news article has multiple companies being mentioned. If more then two names were mentioned in one news article, we considered all of them to be pairs of co-occurrences.
-
Construct a co-occurrences network graph
Yahoo News Website Scraping and Sqlite
We use python’s package BeautifulSoup to scrap all the links of all the news articles from the page.
First, we convert the web page in to a BeautifulSoup object, then we transverse that object and store every ‘href’ tags into a newslink list.
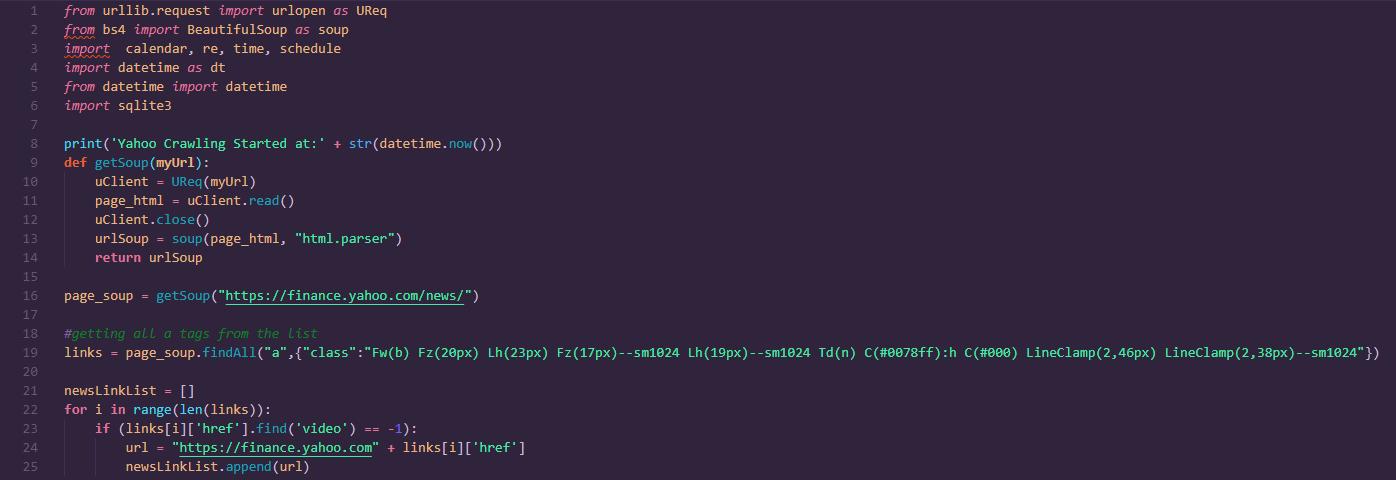
Then we define a class called Article with methods to extract article information from the web page. This information include URL of article, full date and time of publication, author of the article...etc.
Also, we need to create a database for storing the news article. The database table is defined as shown below;
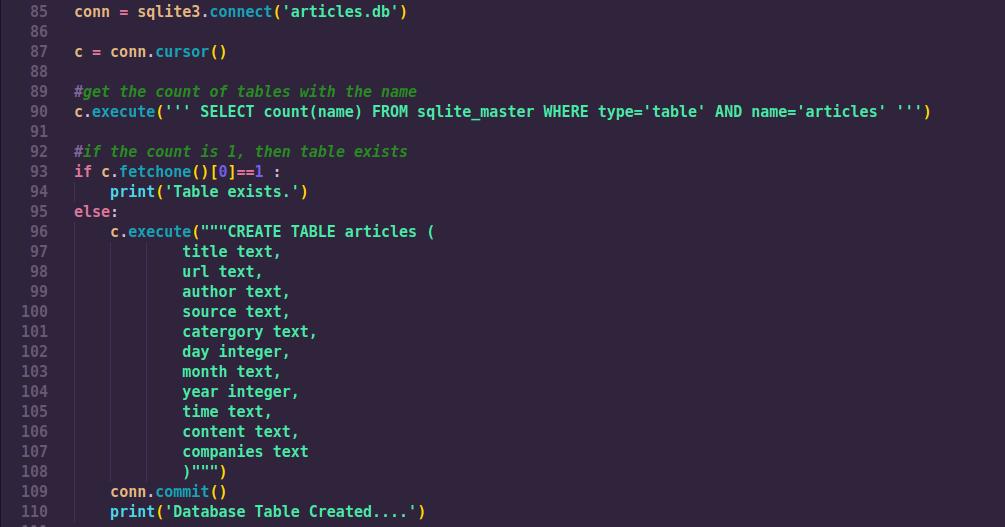
Then finally, we transverse the newLink list and calling the Article class methods on each link and storing that information in an sqlite database.
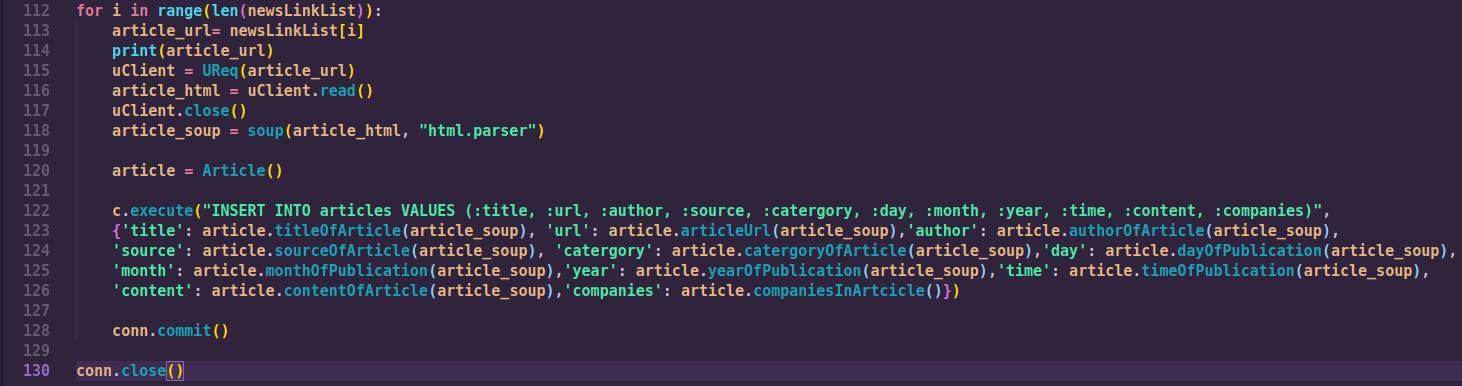
Name Entity Recognition Using Stanford NER
Now that we have the articles stored in a database, we can then start doing some text analysis on the article and see if we can get some useful articles. The goal here is to find out which companies are mentioned in each article, and if multiple companies are mentioned in one article, we treat those as pair of our co-occurrence network graph.
Firstly, we load the data from the database file into a pandas dataframe;
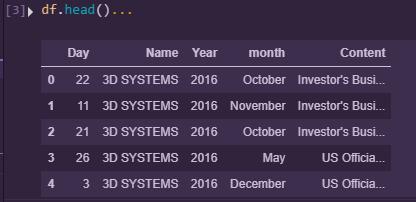
The data in out dataframe is as shown below;
The next step is to transverse each article in this dataframe in use the Stanford NER to find the companies(organizations) mentioned in each article.
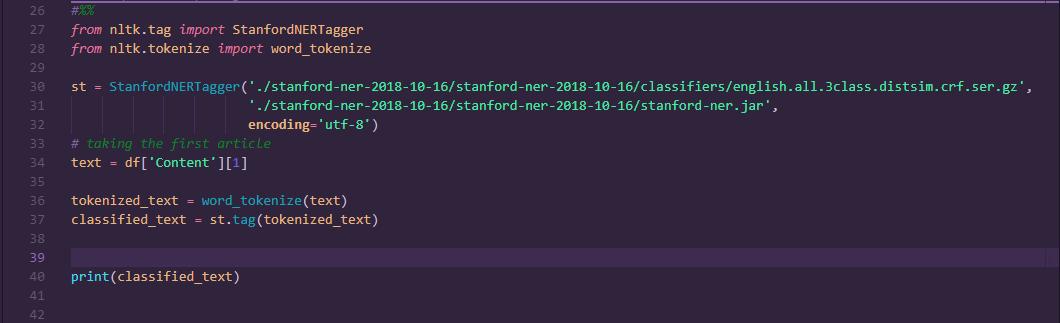
For each article, the Stanford NER will go through each word and classify it as either a place, organization, location or O. If we want all the words classified as ‘organization’ we can run the scripts below;

Displaying the found companies we get;

The next is to repeat this whole process for each article in the database. Then, we can create a co-occurrence matrix as shown below.
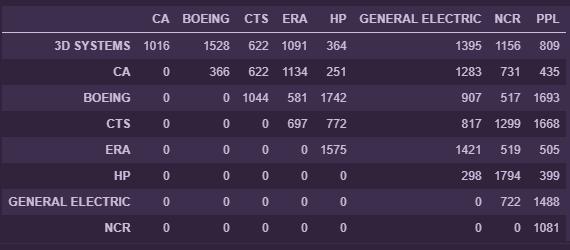
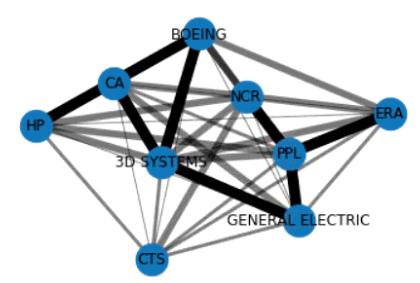
For example, the companies CA and 3D systems have been mentioned together 1016 times in articles. Presenting our result in this format makes it easier to plot a co-occurrence network graph. The next step will be use python library plotly to plot a network graph. In order to plot the co-occurrence network graph, we need the transform the values in the co-occurrence matrix about into a scale of 0.1 to 0.9 as shown below;
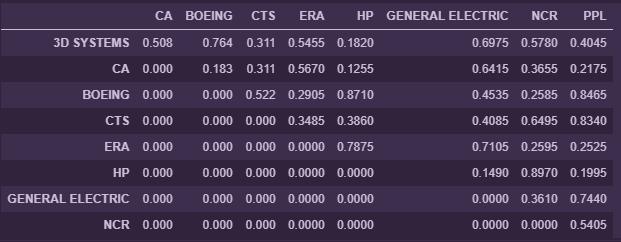
We design the edges in the graph in such a way that their thickness is proportional to how frequent those two nodes they connect occur together in the articles. The result is a weighted co-occurrence network graph as shown below...