Spark Image Classification
Classification using Apache Spark
Apache Spark is a cluster computing system for performing in memory computations in a distributed computing cluster like Hadoop.
MLlib is library of distributed machine learning functions that is shipped with Spark.
In this example we will demonstrate the use of the MLlib Linear SVM classification algorithm.
Singular value decomposition (SVD) is a way to decompose a matrix into some successive approximation. This decomposition can reveal internal structure of the matrix. Since an image is a matrix of pixels we can apply this to extract features in images.
In this example we will classify images as belonging to one of two classes thereby recognizing whether the picture contains a cat or a dog. We can extend this by providing many examples of individual’s faces for facial recognition like facebook does when it tags you and your friends in your photo’s for example.
SVM Support Vector Machines is a supervised learning algorithm, this we first provide already classified examples for it to learn from. The accuracy of the algorithm increases the greater the number of examples.
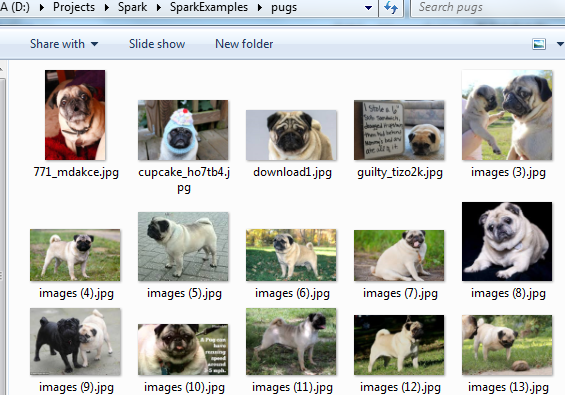
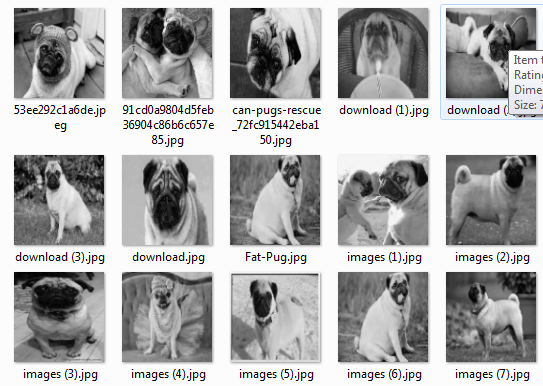
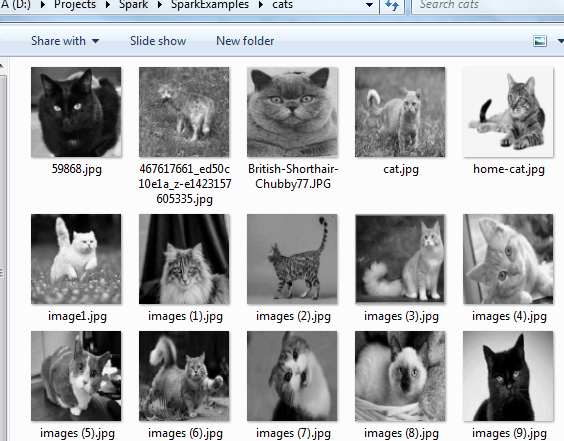
- Obtain a large number of examples of each class. These images of cats we will call class 0 or cats
These images will be class 1 dogs.
- Input for classification algorithms are numerical vector.
- Since an image is a matrix of pixels, we can represent it as a vector by placing each row of pixels one after the other into a vector.
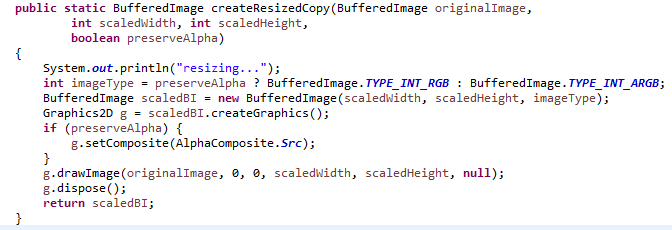
- First we use java to convert each image to a uniform size and convert it to greyscale.
-
- 

- 
- 
- Next we create vectors from the images, we label each vector with a number representing the class the example belongs to.
- For example, for cats we will label as class 1, and dogs we will label as class 0.
- Below write the labelled vectors representing the cats to a csv file.
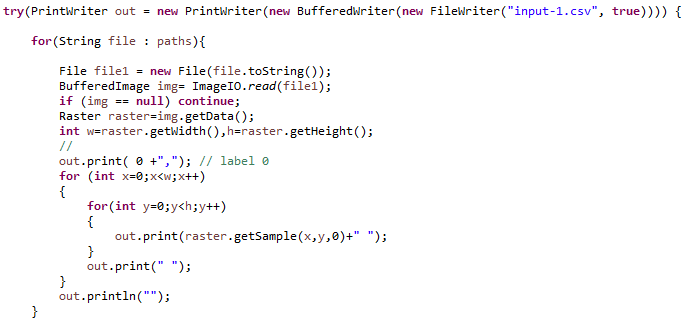
Next add the labelled vectors representing the dogs to this file.
The result should be a csv file containing labelled vectors like this:

You can see vectors are labelled as belonging to either class 0 or 1.
Next create a spark program to submit to your spark cluster.
To do this create a spark context and point it to the master of your cluster. You can also run in local mode for testing, like this.
- Use a map operation to create RDDs from the input csv file.
- A map operates on each RDD to produce another RDD.

The map function we provide creates the labelled vector objects from each line of input.
Next train the SVD algorithm with the RDD.
The arguments are the RDD of training data and the number of iterations to convergence.

After we have trained the SVD we can use it to classify some examples and see how accurate it is: As we did before with the training examples, convert the test images to greyscale and encode them as labelled vectors, then create an RDD.
These are the three test images I will use:
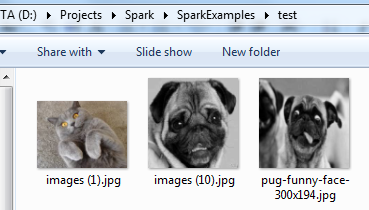

Create labelled vectors for the images to test as we did for the training examples above:

To test the accuracy, we compare the label and the prediction like this:
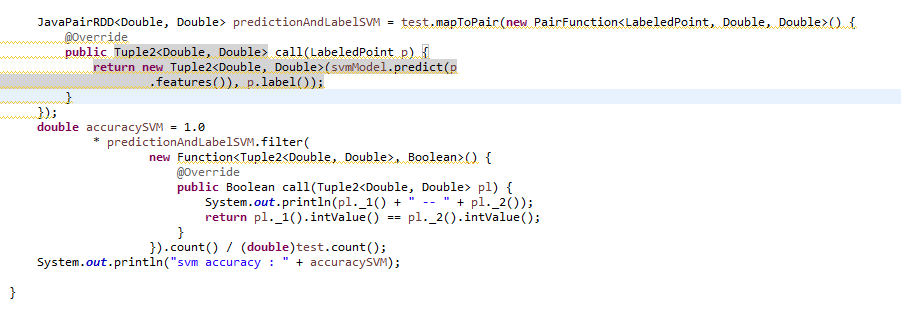
Create a runnable jar and submit the job to your spark cluster.
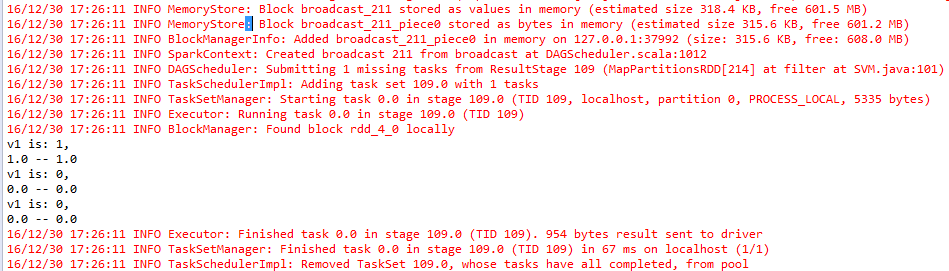
Here you can see our three images have been classified correctly.
You will find that accuracy increases the more training examples we provide.