ELK基礎實務 3
主題:ELK基礎實務 3
作者:Rickey
內容:基本理論HA架構原理,API操作
1. 前言
前段時間我們進行了filebeat的啟動及modules的設定
讓kibana的報表更完善了,並且也了解水平擴充的基本操作
這次我們從理論面出發,了解elasticsearch的理論基礎
並且在沒有kibana的情況下,透過call API來進行基本的叢集檢查
2. 介紹(產品面)
Elasticsearch:
主要作為log收集後,儲存的地方
在Elasticsearch的叢集架構中,要知道所謂的HA架構
2.1 HA高可用性架構
單節點的問題顯而易見,如果節點失去功能,那將會丟失資料
更慘的是,如果整個節點消失,資料也會跟著消失,也因此我們需要建立HA架構
Elasticsearch的高可用性來自於:shard(分片)& replica(副本)
當我們建立多個節點時,資料會被分為多個shard儲存在多個節點
每個shard都會有對應的replica,會分布在與shard「不同」的節點上
那當一台節點失效時,replica就會啟動,將消失的shard復原
這樣整個叢集就可以維持運作!!
以下是一個簡易的節點發生故障時會發生的事情
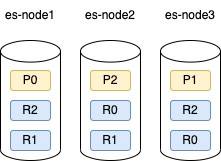
shard=3,replica=2
假設P0,P1,P2是資料A分出來的分片
P0有兩個replica,分別是node2和node3的R0,以此類推
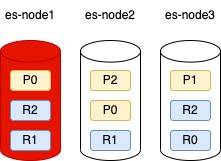
node1壞掉後,P0蒸發,因此P0的replica會晉升為主要的分片
所以我們看到node2的R0變成P0了
這樣我們就可以確保原本的資料A還完整了!
3. 介紹(產品面)
Filebeat:
主要收集來自應用程式產生的log,這些log會儲存在地端檔案夾目錄中
可能的檔案類型是.log、.txt或是.csv等
透過Filebeat我們可以將指定目錄夾,並定時的讀取裡面的資料,再丟給Elasticsearch、Logstash或是buffer做後續的處理
4. 善用Elasticsearch的API
我們可以在kibana的Dev Tools操作API來觀察Elasticsearch的叢集狀況
以下是一些基本的檢查
GET /_cluster/health
GET /_cluster/stats
GET /_cat/nodes?v
GET /_cat/indices?v
GET /_cat/indices?v&s=store.size:desc #desc是降冪的意思
在執行後我們可以看到類似這樣的訊息

5. 當Kibana無法用時,該如何是好?
那我們可以透過curl的指令,直接對elasticsearch呼叫API
curl -X GET "https://127.0.0.1:9200/_cluster/health" -k -u elastic:<你的密碼>
就會有一坨輸出

這個情境在實務上很常遇到,我們不會一直使用kibana因為會反覆的切換視窗
也可能因為地點局限和權限問題,我們只能使用terminal
6. 結語&Recap
Recap:介紹了shard&Replica的運作,以及與HA的關係。介紹基本的檢查API
本篇文章注重再讓讀者了解HA的重要性,並且降低讀者對kibana的依賴性,進而使用terminal進行操作
希望透過這次的文章,讓讀者更了解elasticsearch在產品中的定位,以及對產品的重要性
也可以有更多元的監控手段