MongoDB(v3.3)-資料模型及java開發
主題: |
MongoDB(v3.3)-資料模型及java開發 |
文章簡介: |
介紹MongoDB的資料模型與功能強大的API及如何使用java開發基於MongoDB的應用程式。 |
作者: |
林政儀 |
版本/產出日期: |
V1.0/2016.11.29 |
1. 前言
本篇適用閱讀對象為對MongoDB有初步的認知與實作經驗,因此本篇將著重於MongoDB(v3.3)的資料模型及各種API功能、操作概念,並使用java快速開發基於MongoDB的應用程式。
2. 目的
• 了解MongoDB的資料模型概念
• 了解MongoDB強大的API如何操作資料。
• 學習在java快速開發基於MongoDB的應用程式。
3. 開始前準備
• MongoDB(v3.3)
• Robomongo(v0.9.0)
• Java 1.8。
• Eclipse(Neon v4.6.1)。
• 愉悅的心情。
4. MongoDB的資料模型(Data Models)
大家都知道MongoDB是schemaless的DB結構,那為什麼還要提資料結構呢?不就是JSON這種資料結構的概念嗎?還有什麼把戲?重點就是因為太自由了,所以如果沒有一個很好的規劃,那將會是一場災難。
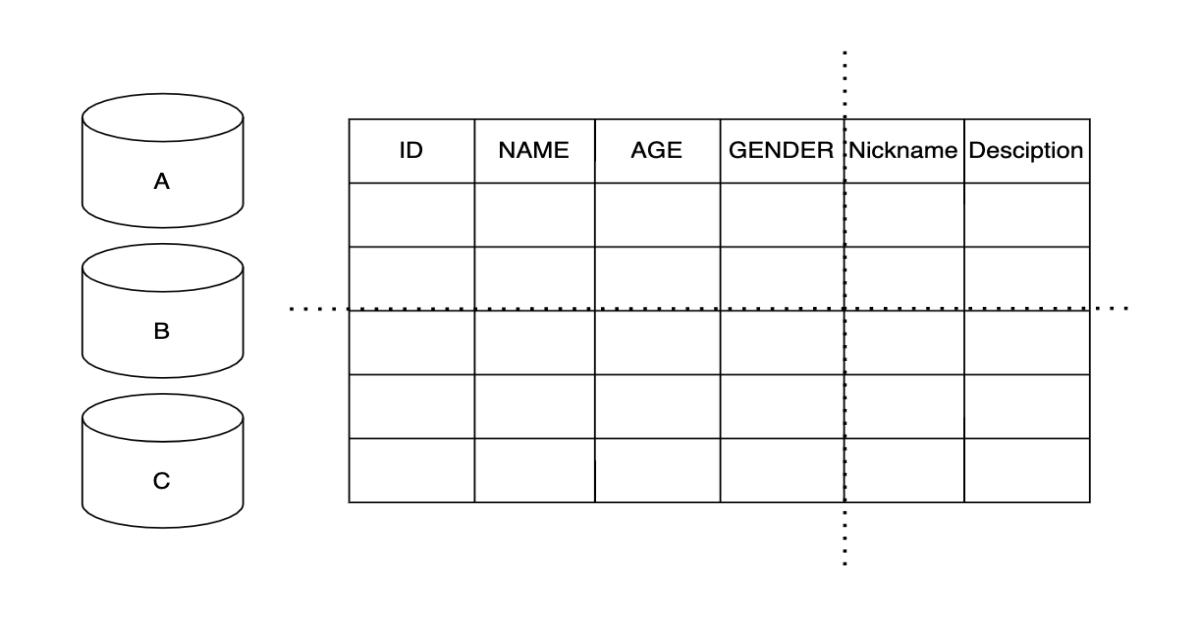
我們先來看看傳統RDB典型的一對多關聯表:
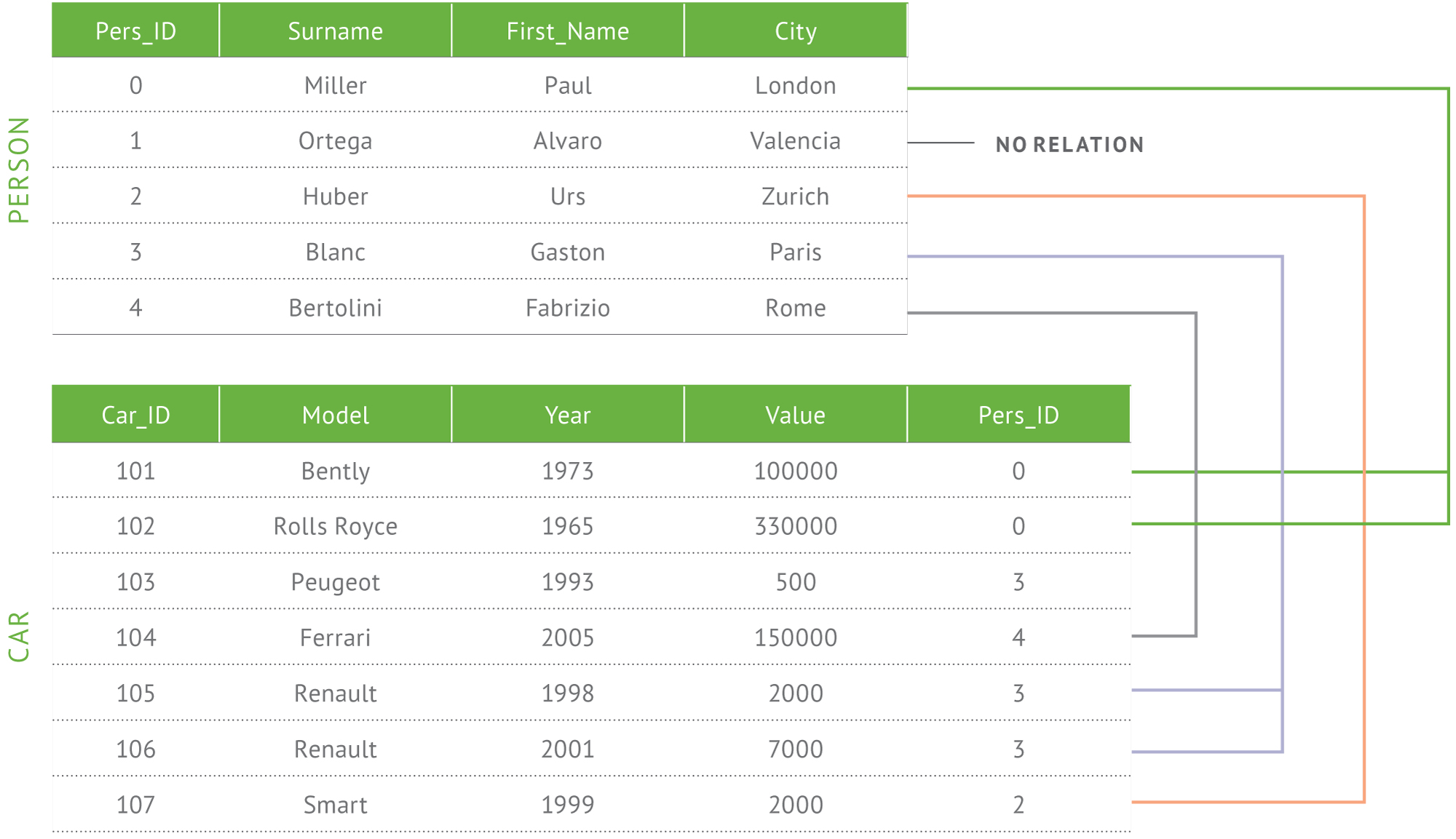
上圖在描述誰擁有那些車子這件事。請注意” 誰擁有那些車子”這句話,這句話的角度是由人去看車子,但在表中卻是由車子去記擁有我的是誰這件事,這並不是一個很直觀的概念。
但如果用Document(也就是json的概念,MongoDB用document稱為一筆資料)的角度來描述的話,情況就不同了:
{ "_id": 0, "surname": "Miller", "firstName": "Paul", "city": "London", "cars": [ { "model": "Bently", "year": 1973, "value": 100000 }, { "model": "Rolls Royce", "year": 1965, "value": 330000 } ] } |
{ "_id": 0, "surname": "Ortega", "firstName": "Alvaro", "city": "Valencia", "cars": [ ] } |
你看,是不是一眼就看出Paul有兩台車、Alvaro一台車也沒有 (所以馬上就可以知道Paul是有錢人、Alvaro是窮鬼!)。
其實這樣在操作上也會非常直覺,因為只要找出人也就可以馬上知道他有哪些車子。相信有使用過Hibernate或JPA這種ORM技術的人都知道,操作Entity時直接從field拿出它所一對多的東西時是多麼愉悅的事情。
再來看一個複雜一點的case:
|
|
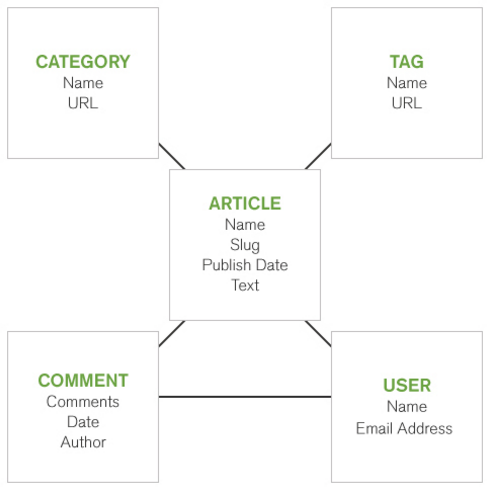
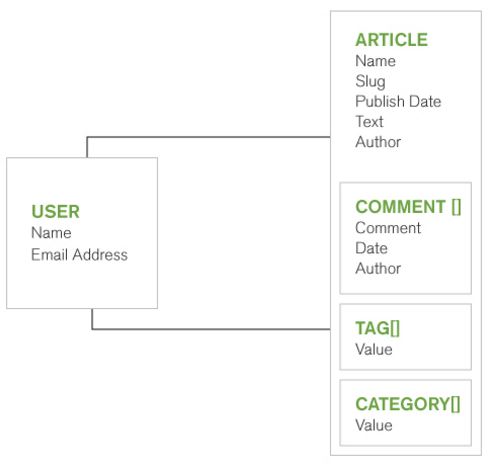
左圖為傳統RDB在描述一個部落格狀態,右圖為MongoDB使用Document來描述這種狀態,是否更一目了然呢?除此之外這種資料格式還有性能跟可擴展性的優勢:
• 不必讀取硬碟物理位置多處來讀寫資料。一個Document被視為單一對象存放在硬碟的單一物理位置;而RDB在join時需要讀取多個硬碟的物理位置,在讀寫效率上有根本性的差異。
• 自包含(self-contained)的特性使的在分片(sharding)簡單許多,因為一份Document不會來自不同地方,因此可以輕鬆的橫向擴充,也不必擔心跨節點(cross-node)的join效能問題。
另外,在同一個Collection裡的Document所擁有的數據結構應該是要相同。就像在java裡使用List管理一堆相同性質物件一樣,你在for each時就可以用同一個角度來看每一個元素。
例如:
List<People> peopleList = new ArrayList<>(); peopleList.add(new People("金城武")); peopleList.add(new People("林志玲")); |
在peopleList裡你所管理的是一群同性質的物件,for each操作上就不會產生歧異。
但如果你是這樣寫:
List<Object> somethingList = new ArrayList<>(); somethingList.add(new People("川普")); somethingList.add(new Car("帕加尼-風神")); |
雖然沒有人說不行,但是你在for each時就會因為大家結構不一樣而非常難操作。
MongoDB也是一樣,要放結構不一樣的東西是你的自由,但站在操作性的角度上我想一般人自然都會讓它們一樣。
好了,那麼現在來說說RDB各種關聯模式與MongoDB的關係吧。
一對一
{ "_id": "joe", "name": "Joe Bookreader", "address": { "street": "123 Fake Street", "city": "Faketon", "state": "MA", "zip": "12345" } } |
其實就像是傳統RDB一對一的關係,用意在於封裝或隔離同個領域的資訊,沒什麼特別的。真要說的話就跟上面提過的一樣,不需要再去join,操作上也直覺方便;硬碟也可以從一個物理位置讀取就好而不需要從多個物理位置取得資料。
一對多
嵌入式資料模型 (Embedded Data Models) |
|
{ "_id": "joe", "name": "Joe Bookreader", "addresses": [ { "street": "123 Fake Street", "city": "Faketon", "state": "MA", "zip": "12345" }, { "street": "1 Some Other Street", "city": "Boston", "state": "MA", "zip": "12345" } ] } |
|
關聯式資料模型 (References Data Models) |
|
{ "_id": "joe", "name": "Joe Bookreader", "addresses": [ 111,222 ] } |
{ "_id": "joe", "name": "Joe Bookreader" } |
{ "_id": 111, "street": "123 Fake Street", "city": "Faketon", "state": "MA", "zip": "12345" } { "_id": 222, "street": "1 Some Other Street", "city": "Boston", "state": "MA", "zip": "12345" } |
{ "_id": 111, "street": "123 Fake Street", "city": "Faketon", "state": "MA", "zip": "12345", "people": "joe" } { "_id": 222, "street": "1 Some Other Street", "city": "Boston", "state": "MA", "zip": "12345", "people": "joe" } |
• 嵌入式資料模型(Embedded Data Models)
很顯而易見的,就是把這個人擁有的地址放到他的address裡,非常輕鬆愉悅,但當資料會不斷成長時,這種資料結構也就會漸漸出現效能問題,而且單一Document有16MB資料上限(若有超過16MB資料量的需求,則可以考慮使用GridFS )。所以如果應用場景裡嵌入的field具有不斷成長的特性,那麼就不太適合採用此資料結構,不過這種資料模型在讀取跟更新時有較好的操作性。
• 參照式資料模型(References Data Models)
沒錯!它就是RDB的核心概念「關聯」。我知道你現在的OS是:「可是先前才說了一堆非關聯的好處,怎麼現在又繞回來了勒?」,因為在某些情況下,關聯還是必然存在的囉。
例如買家跟訂單的關係,因為買家的訂單量會不斷成長,這種情況並不適用嵌入式資料模型,你勢必要將買家跟訂單拆分兩個Collection:
Buyer Collection |
Order Collection |
{ "_id": 0, "name": "Aery", "phone": 1234567 } |
{ "_id": 0, "buyer": { "name": "Aery", "phone": 1234567 }, "goods": "Apple" } { "_id": 1, "buyer": { "name": "Aery", "phone": 1234567 }, "goods": "Note Book" } |
沒錯!聰明如你一定馬上就知道問題所在,今天買家改電話時就要去每一筆訂單改買家的電話,這是不合理的做法。所以你勢必會將資料模型修改為References讓它連結過去:
Buyer Collection |
Order Collection |
{ "_id": 0, "name": "Aery", "phone": 1234567 } |
{ "_id": 0, "buyer_id": 0, "goods": "Apple" } { "_id": 1, "buyer_id": 0, "goods": "Note Book" } |
但因為MongoDB並沒有join這種概念,所以遇到這種情況就必須發動兩次Query來取出(在MongoDB的Reference會提到如何取出)全部資料。例如你只有訂單資訊,想從訂單找出人是誰的話,就必須先查出該訂單,然後再從訂單拿到buyer_id之後再去查Buyer找到該買家。上述這種參照方式稱為Manual References 。
你現在應該在想:「還要再Query一次,怎麼這麼麻煩?」對,沒錯,它就是這樣。但也說不上是好是壞,而是視需求來設計。當然,MongoDB開發人員也不是笨蛋,也知道這樣非常麻煩,所以又有稱為DBRefs 的方式出現,它雖然在commandline底下操作時一樣要手動去Query第二次才能取出資料,但它的優點在於許多driver已經幫你寫好這個第二動的查詢,只要資料這樣存放:
Buyer Collection |
Order Collection |
{ "_id": 0, "name": "Aery", "phone": 1234567 } |
{ "_id": 0, "buyer": { "$ref": "Buyer", "$id": "0", "$db": "MongoTest" }, "goods": "Apple" } { "_id": 1, "buyer": { "$ref": "Buyer", "$id": "0", "$db": "MongoTest" }, "goods": "Note Book" } |
然後使用driver時只要操作一次(但其實driver會發動兩次Query),就可以返回完整資料:
{ "_id": 0, "buyer": { "name": "Aery", "phone": 1234567 }, "goods": "Apple" } { "_id": 1, "buyer": { "name": "Aery", "phone": 1234567 }, "goods": "Note Book" } |
而DBRefs其實也是提供了一個共通的reference格式(就像介面)來表達Collection的關聯性。
關於參數意義如下:
$ref |
必要 |
要參照的collectoin名稱。 |
$id |
必要 |
要參照該筆document的_id。 |
$db |
非必要 |
要參照的DB name。 |
*這個順序是有意義的,使用時必須按照這個順序描述參照。
官方有提到一點:
Unless you have a compelling reason to use DBRefs, use manual references instead.
意思大概是是沒事少用DBRefs,還是用Manual References吧。不過我還不清楚為什麼不能常用,這個方式直覺且在操作java driver時也是輕鬆寫意,或許是有什麼效率上的考量吧。
另外MongoDB並沒有像RDB一樣有constraint存在。例如Order的存在是基於Buyer,沒有Buyer就沒有Order,因此RDB的constraint可以保護當還有Order關聯到Buyer時是不可以刪除Buyer的。因此在MongoDB的應用程式上就必須控制好這種情況,避免孤兒關聯出現。
多對多
這種關係在Document的資料描述下,不再是困擾。在RDB裡正規化的多對多關聯必須多出一張表來描述這兩張表多對多的關係。例如一個人可以喜歡多個水果,一個水果可以被多個人喜歡
,如下圖所示:
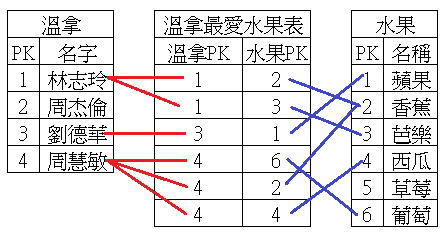
這種描述方式會橫跨三張表,也會造成CRUD的操作不便。
若改成Document就可以這樣描述:
{ "name": "林志玲", "favorite_fruit": [ "香蕉", "芭樂" ] } |
{ "name": "周杰倫", "favorite_fruit": [ ] } |
{ "name": "劉德華", "favorite_fruit": [ "蘋果" ] } |
{ "name": "周慧敏", "favorite_fruit": [ "葡萄", "香蕉", "西瓜" ] } |
或者反過來讓水果去記喜歡吃自己的是誰也可以,一切端看情境而決定資料模型。大多數時候是取決於domain knowhow,這也會讓程式跟domain更為貼切。
樹狀結構
其實就跟RDB描述樹狀結構一樣。MongoDB的document裡自帶上層或下層節點的_id。
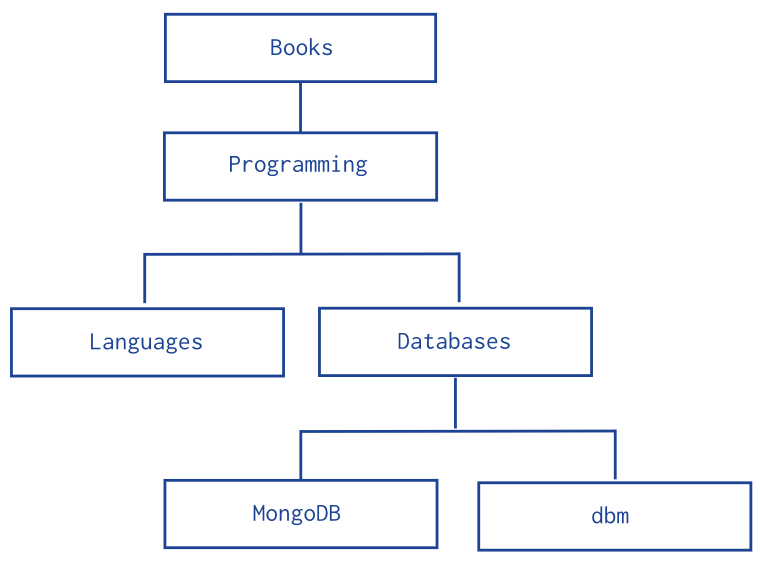
• 父類參照 |
• 子類參照 |
[ { _id: "Books", parent: null }, { _id: "Programming", parent: "Books" }, { _id: "Languages", parent: "Programming" }, { _id: "Databases", parent: "Programming" }, { _id: "MongoDB", parent: "Databases" }, { _id: "dbm", parent: "Databases" }, ] |
[ { _id: "Books", children: [ "Programming" ] }, { _id: "Programming", children: [ "Databases", "Languages" ] }, { _id: "Languages", children: [] }, { _id: "Databases", children: [ "MongoDB", "dbm" ] }, { _id: "MongoDB", children: [] }, { _id: "dbm", children: [] }, ] |
這種描述方式非常直覺,而父類參照也是RDB會使用的方式。這種方式也是所謂的鏈結(linked)資料結構,這種資料結構在插入跟移動時非常快速,因為只要修正該節點位於整棵樹中的位置,往下包含的所有節點將會一起被調整。
但這種資料結構會有爬節點緩慢的問題,例如你想找位於第5層的節點,你就必須從1開始往下找,因為資料數據裡並沒有描述自己位於整個樹狀結構的位置資訊。
• 祖先們的庇佑 ( Array of Ancestors )
(因為英文使用Ancestors了這個詞,我想應該跟祖宗十八代是一樣的意思吧,其實是我想不到什麼好翻譯啊~)
因為上述兩種參照方式存在的缺點,所以在MongoDB裡可以利用array來存放歷代的祖先們,將路徑資訊存放起來:
[ { _id: "Books", ancestors: [ ], parent: null }, { _id: "Programming", ancestors: [ "Books" ], parent: "Books" }, { _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" }, { _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" }, { _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" }, { _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } ] |
將樹系的資訊存放於自身的document裡面,可以有效的根據樹系資訊來下一個查詢就找出想要的節點。但缺點就是當你插入或移動節點,往下的樹系都必須更新ancestors來確保資料完整性。
簡單來說就是將路徑攤平成一個字串存放,其實概念也是跟祖先們的庇佑一樣,將樹系資訊存起來使用,這也是RDB常使用的反正規化方法。
[ { _id: "Books", path: null }, { _id: "Programming", path: ",Books," }, { _id: "Languages", path: ",Books,Programming," }, { _id: "Databases", path: ",Books,Programming," }, { _id: "MongoDB", path: ",Books,Programming,Databases," }, { _id: "dbm", path: ",Books,Programming,Databases," } ] |
這樣做之後就可以使用MongoDB強大的regular搜尋來查找節點。
• 數值嵌套 ( Nested Sets )
一個優化樹狀結構查詢的方法。
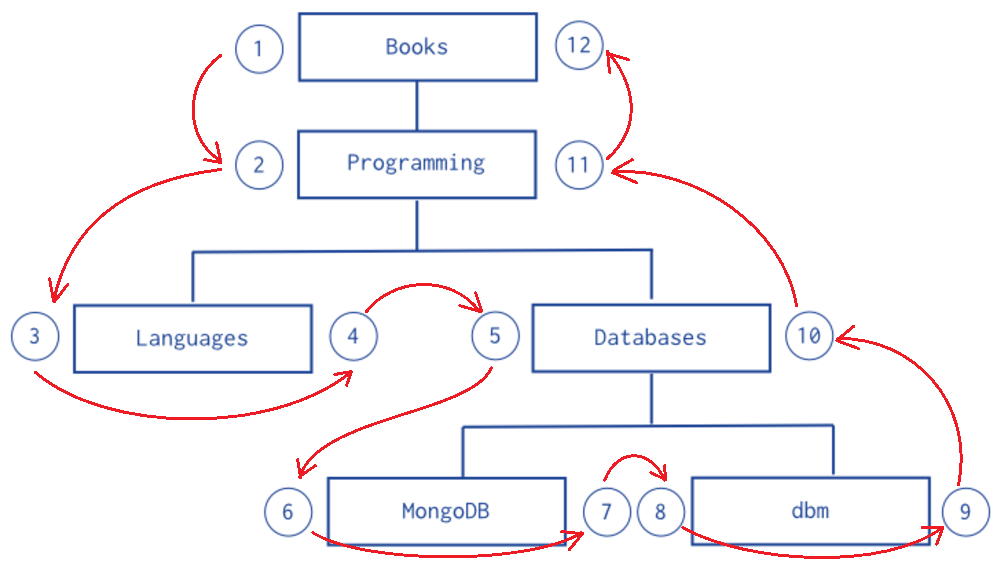
[ { _id: "Books", parent: 0, left: 1, right: 12 }, { _id: "Programming", parent: "Books", left: 2, right: 11 }, { _id: "Languages", parent: "Programming", left: 3, right: 4 }, { _id: "Databases", parent: "Programming", left: 5, right: 10 }, { _id: "MongoDB", parent: "Databases", left: 6, right: 7 }, { _id: "dbm", parent: "Databases", left: 8, right: 9 } ] |
每個節點都存放左右兩個數值,由節點逆時針往下走,每遇到節點就編號。編完之後就可以利用數值包夾的方式,下一個查詢就抓出整個樹系。
例如我想找Programming底下有哪些書,那麼我條件只要下左數值介於2~11之間,就可以一次找出整個樹系。依樣畫葫蘆,如果想找Databases底下的書,那就是左數值介於5~10之間就可以查出來了。
小結一下
MongoDB將不再限制你應該怎麼存放跟使用你的資料,而是將自由返還給使用者,也因為過於自由,如何根據情境選擇對應的資料模型將會是程式設計師的挑戰。
或許有人會有疑惑,想說ORM技術現在這麼成熟也有許多應用了,我何必特別選用一個不熟悉的DB來滿足這種開發需求就好了呢?我個人認為ORM是一層轉換層,隔在業務邏輯跟RDB中間,自然會有效率上的問題。而且很多情況下,你還是必須下HQL或JPQL這種類原生的SQL來查詢跟mapping你的資料,其實在某種程度上也並不是真正的這麼直覺,而且有時候也因為多出了一層,出問題時在追蹤上就會複雜許多。
而MongoDB原生就是如此設計的結構,在程式的操作跟效能上自然會快速許多,而且MongoDB也有其他諸如高併發性、橫向擴展、schemaless的高彈性等等的優點是傳統RDB的瓶頸,不過這也是犧牲強一致性而換來的優點,所以並沒有誰最好的結論,而是視情境選擇最佳方案。
5. 建立MongoDB專案
首先去官網下載 java 的 driver ,所使用的版本是v3.3.0。官方提供四種driver來因應不同開發需求,不過有基於一般的MongoDB應用開發我們選擇mongo-java-driver就好了。
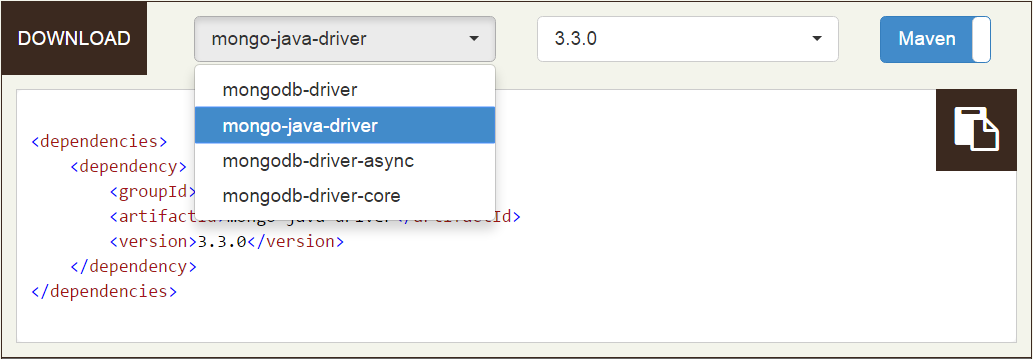
可以選擇使用maven或gradle的專案管理來取得lib,不過我們只是要簡單的測試而已,所以就直接按DOWNLOAD 來下載jar,接著把它放在專案底下include之後就好啦。
1.%2 建立MongoClient
• 快速建立
MongoClient mongoClient1 = new MongoClient(); // 預設連localhost:27017 MongoClient mongoClient2 = new MongoClient("localhost"); // 預設連27017 MongoClient mongoClient3 = new MongoClient("localhost", 27017); |
• 基於副本集建立(它會自動發現primary,但必須提供相關的機器才可以。)
List<ServerAddress> replicaSetServerList = new ArrayList<>(); replicaSetServerList.add(new ServerAddress("localhost", 27017)); replicaSetServerList.add(new ServerAddress("localhost", 27018)); replicaSetServerList.add(new ServerAddress("localhost", 27019)); MongoClient mongoClient4 = new MongoClient(replicaSetServerList); |
• 使用連線字串建立
String connectionString = "mongodb://localhost:27017,localhost:27018,localhost:27019"; MongoClientURI mongoClientURI = new MongoClientURI(connectionString); MongoClient mongoClient5 = new MongoClient(mongoClientURI); |
• 授權建立
String userName = "使用者帳號"; String database = "DB名稱"; char[] password = "密碼".toCharArray(); MongoCredential credential = MongoCredential.createCredential(userName, database, password); List<MongoCredential> mongoCredentialList = Arrays.asList(credential); MongoClient mongoClient6 = new MongoClient(new ServerAddress("localhost"), mongoCredentialList); |
操作MongoClient
• 取得DB
MongoDatabase db = mongoClient.getDatabase("dbName"); |
• 取得Collection
MongoCollection<Document> collection = db.getCollection("collectionName"); |
• 接著就可以操作該collection的CRUD囉
collection.insertOne(document); collection.find(filter); collection.updateOne(filter, update); collection.deleteOne(filter); |
• 使用完記得關閉連線
MongoClient mongoClient = new MongoClient(); try { new MongoTest().gogogo(mongoClient); } finally { mongoClient.close(); } |
6. MongoDB CRUD之Create

• 每一個Document都一定會有一個_id的field,它就如同RDB的PrimaryKey,但在MongoDB的世界裡PrimaryKey就是只有它,不會有別人。
• _id不能被移除不能為空,如果寫入時沒特別指定,則MongoDB會自動幫妳生成一個BS O N 的ObjectId。
• insert時如果DB或Collection不存在的話,MongoDB會自動幫你建立,無需事先創建(因為schemaless嘛!)。
insert有三種方法:
B. db.collection.insertOne() New in version 3.2
C. db.collection.insertMany() New in version 3.2
語法結構為:

Parameter |
Type |
Description |
document |
document/array (Required) |
就是要insert的document囉。 可以為單一{}的document或者是[{},{},…]多個document。 |
writeConcern (寫入關注) |
document |
主要在關切寫入時的完整度,這跟replica sets與sharded clusters有密切關係。 詳細說明在後面的writeConcern章節說明。 |
ordered (排序寫入) |
Boolean [true,false] (Default:true) |
在當insert的document為array時生效。 true:進行有序寫入(single thread)。 也就是array中的上一個document處理完才會處理下一個。所以當其中一個document處理爆炸時,他就會不處理接下來的document,然後返回該筆資訊並附上錯誤訊息。 false:進行無序寫入(multi thread)。 根據這裡 的描述,MongoDB進行bulk寫入時會啟動多個thread來拆分array資料處理,所以想當然爾其中一個document寫入爆炸時,其他thread仍繼續處理,所以最後會附上成功幾筆、錯誤幾筆的訊息,並且將所有爆炸的document全部返回給你。也因為是multi thread,所以它效率較好。 |
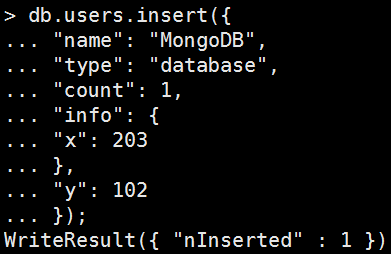
• 寫入一筆資料吧
Mongo Command |
|
db.users.insert({ name: "MongoDB", type: "database", count: 1, info: { x: 203 }, y: 102 }); |
執行結果:
WriteResult({ "nInserted" : 1 })是寫入回傳的結果。 其實很一目了然,它在跟你說成功寫入1筆啦~ |
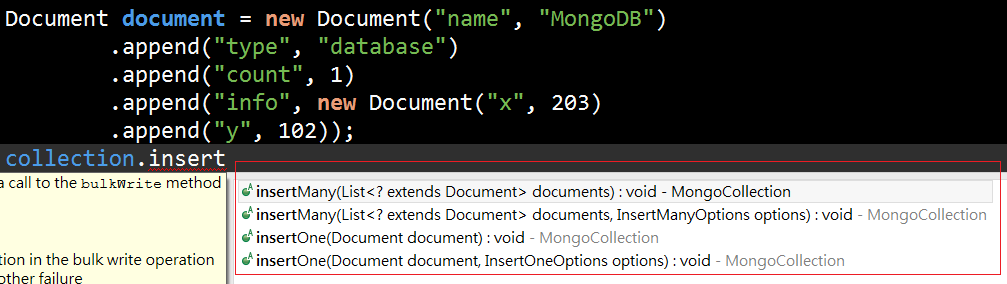
Java Operate |
|
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到insert這個方法了。
|
|
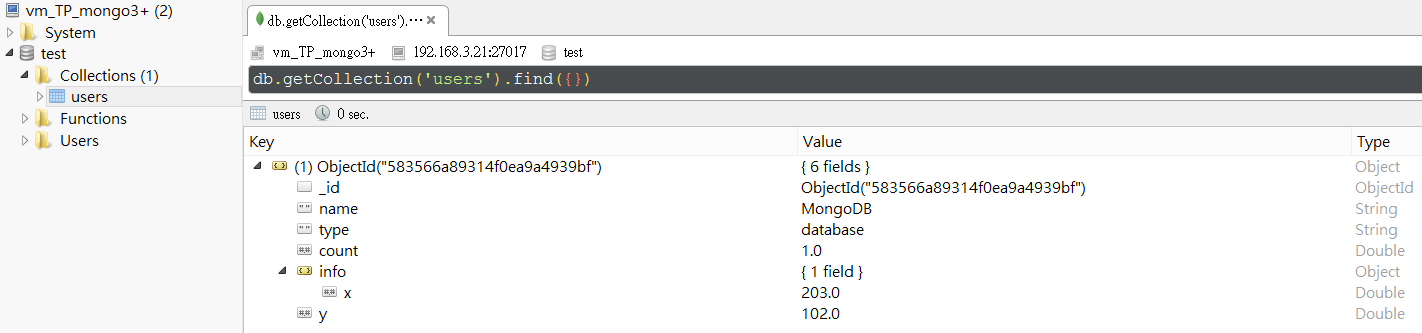
從Robomongo就可以查到剛剛被insert的那筆資料。
• 寫入多筆資料吧
Mongo Command |
|
db.products.insert( [ { _id: 11, item: "pencil", qty: 50, type: "no.2" }, { item: "pen", qty: 20 }, { item: "eraser", qty: 25 } ] ); |
執行結果:
|
可以很明顯看到回傳結果叫做BulkWriteResult,意思就是當array寫入時MongDB將視為一種Bulk批量寫入。 從結果可以很顯知道它在告訴我們寫入成功筆數、失敗筆數、等等資訊,可以從BulkWriteResult 獲得更多資訊。 |
|
Java Operate |
|
嗯,就是沒有這個方法囉。 |
|
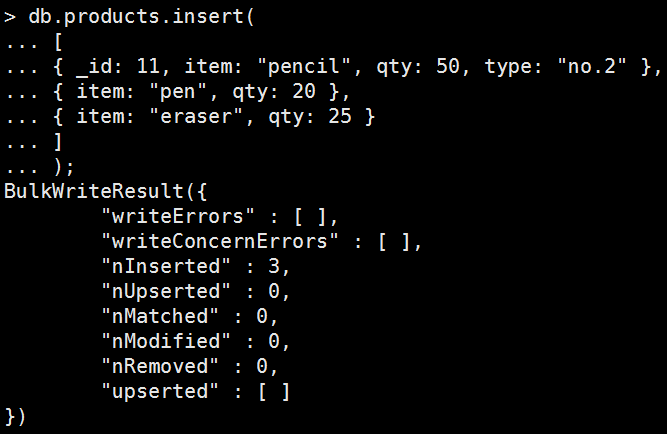
從Robomongo就可以查到剛剛被insert的那些資料囉。
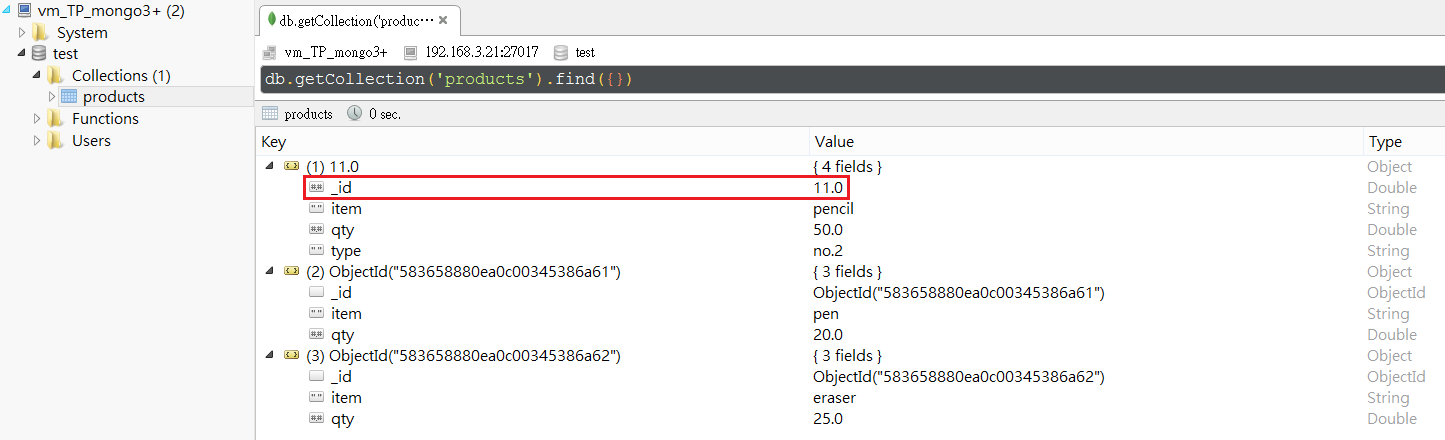
仔細看可以發現第一筆_id為我們指定進去的11。那麼如果我們又寫入一筆_id:11的資料勒?是的,跟你想的一樣,它會爆炸!所以我們來看看爆炸訊息吧~
• 寫入幾筆會爆炸的資料吧
Mongo Command |
db.users.insert( [ {_id: "1", name: "A", age: 3}, {_id: "2", name: "B", age: 5}, {_id: "2", name: "C", age: 9}, {_id: "4", name: "D", age: 7}, {_id: "5", name: "E", age: 3}, {_id: "5", name: "E", age: 5} ] ); 執行結果:
爆炸啦~~~ |
Java Operate |
嗯,就是沒有這個方法囉。 |
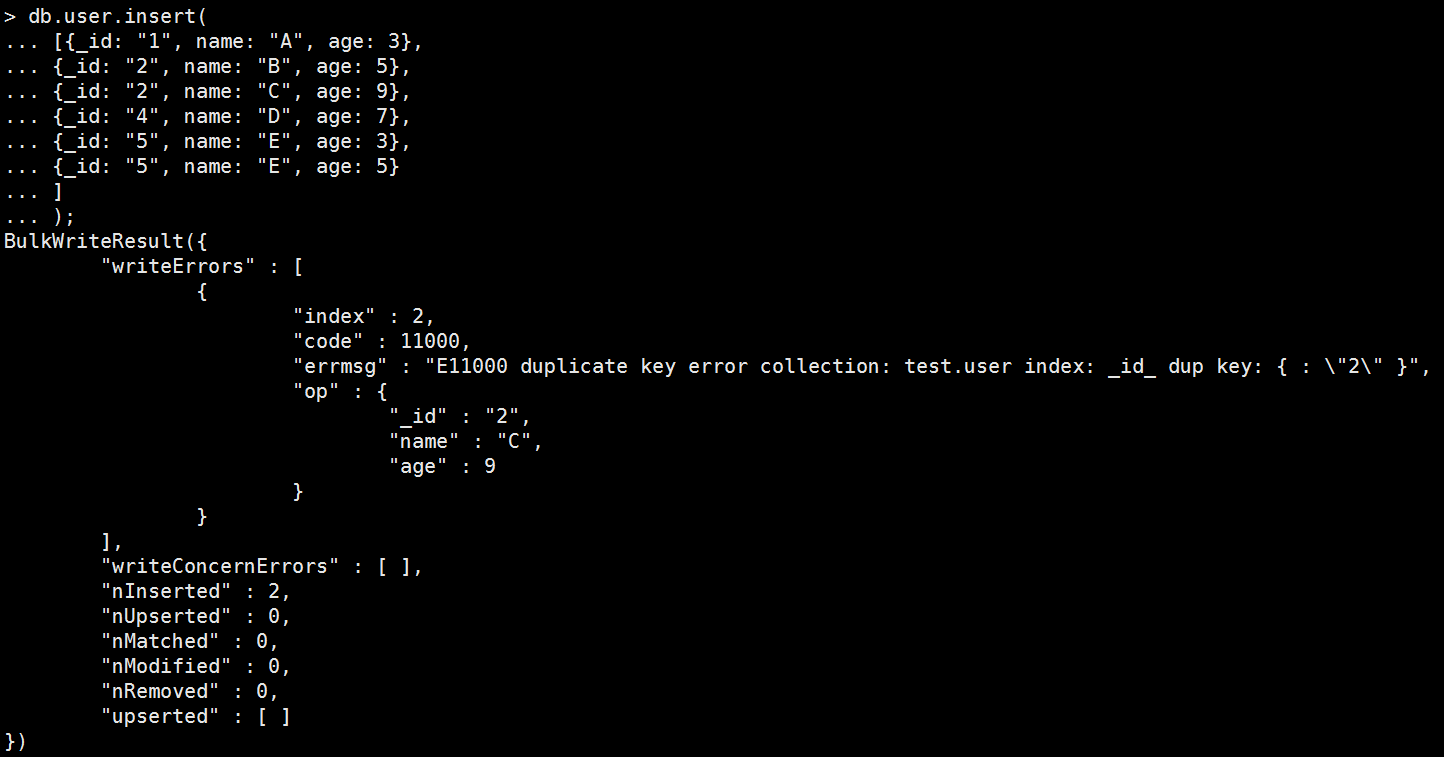
在回傳訊息裡,我們可以看到writeErrors裡所包含的就是炸掉那筆資料,因為C想寫入_id:2的資料,但上一個人B已經先用掉了,因此發生_id重複的錯誤。
然後妳會發現nInserted是2,是因為ordered(排序寫入)預設是true。表示現在是有序寫入,因此寫到爆炸那筆之後就不處理了,他就會返回當下錯誤那筆document跟已經處理過的資訊給你,然後你就得視業務邏輯來看要做什麼處理囉。
如果你的寫入資料並沒有相依關係的話,就可以使用ordered:false的無序寫入囉。
• 使用ordered:false來寫入幾筆會爆炸的資料吧
*寫入資料前先把users這個collection刪掉吧。
Mongo Command |
db.user.insert( [ {_id: "1", name: "A", age: 3}, {_id: "2", name: "B", age: 5}, {_id: "2", name: "C", age: 9}, {_id: "4", name: "D", age: 7}, {_id: "5", name: "E", age: 3}, {_id: "5", name: "E", age: 5} ], { ordered: false } ); 執行結果:
|
Java Operate |
嗯,就是沒有這個方法囉。 |
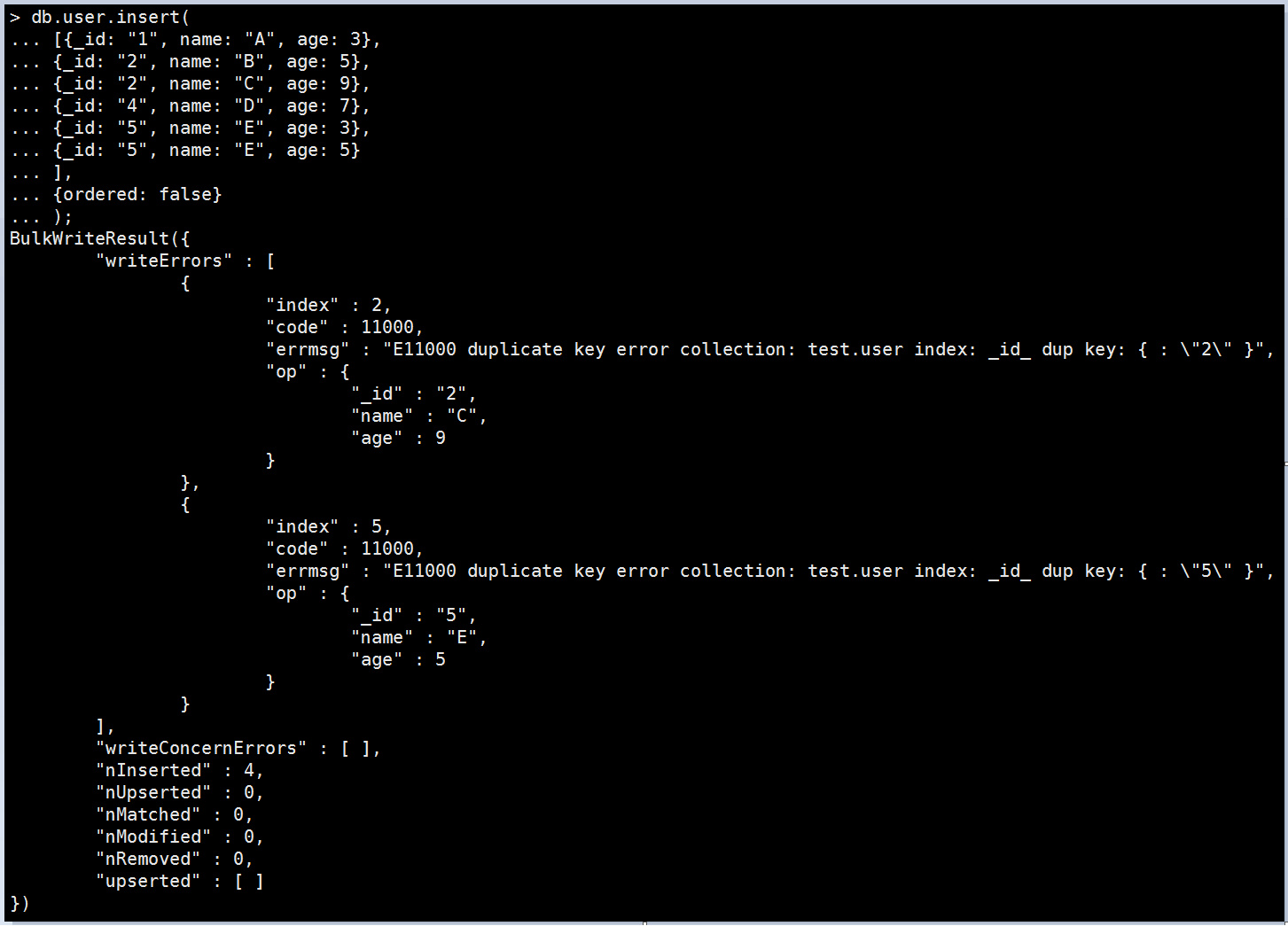
從結果可以一目了然知道寫入4筆成功,2筆爆炸並回傳原因跟該筆資料給你做後續處理囉。
語法結構為:

*眼尖的同學應該發現ordered不見啦,因為ordered是針對array時的操作,這個method不接受array,所以自然沒有這個設定囉。
參數意義跟”A.db.collection.insert() ”一樣,所以就不贅述了。
• 來寫入一筆資料吧
*寫入資料前先把users這個collection刪掉吧。
Mongo Command |
|
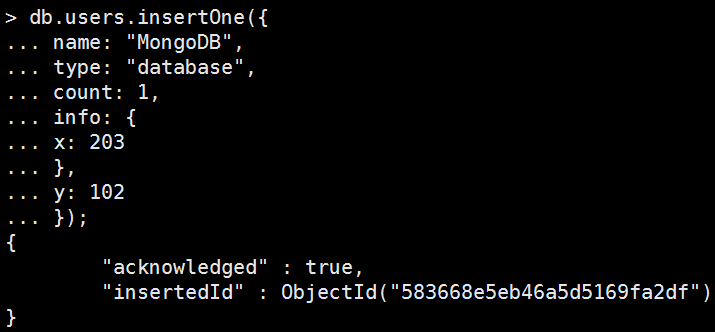
db.users.insertOne({ name: "MongoDB", type: "database", count: 1, info: { x: 203 }, y: 102 }); |
執行結果:
|
Java Operate |
|
Document document = new Document("name", "MongoDB") // .append("type", "database") // .append("count", 1) // .append("info", new Document("x", 203) // .append("y", 102)); // System.out.println(document.toJson()); collection.insertOne(document); System.out.println(document.toJson()); |
|
執行結果:
|
|

• 來寫入會爆炸的資料吧
先寫入指定_id的一筆資料:db.products.insertOne( {_id: "1", name: "A", age: 3} );
接著分別操作command跟java吧
Mongo Command |
|
db. user.insertOne( {_id: "1", name: "A", age: 3} ); |
執行結果:
|
Java Operate |
|
Document document = new Document("_id", "1") // .append("name", "A") // .append("age", 3); System.out.println(document.toJson()); collection.insertOne(document); System.out.println(document.toJson()); |
|
執行結果:
|
|
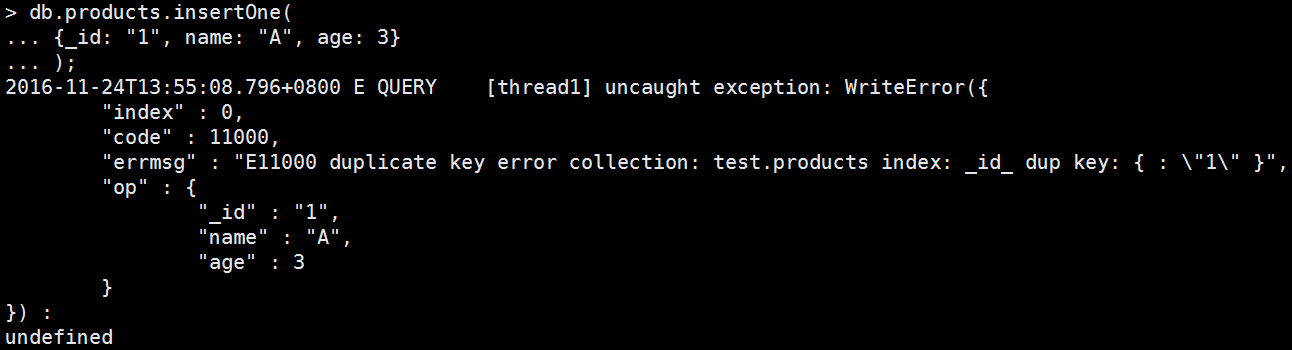

拋出exception了啊啊啊!其實也不是很意外啦,只是在command底下他竟然也拋出exception了,怎麼回事?
其實MongoDBv3.2是採用SpiderMonkey 的javascript引擎,所以我們只要用js角度想著要怎麼操作MongoDB就很簡單啦~
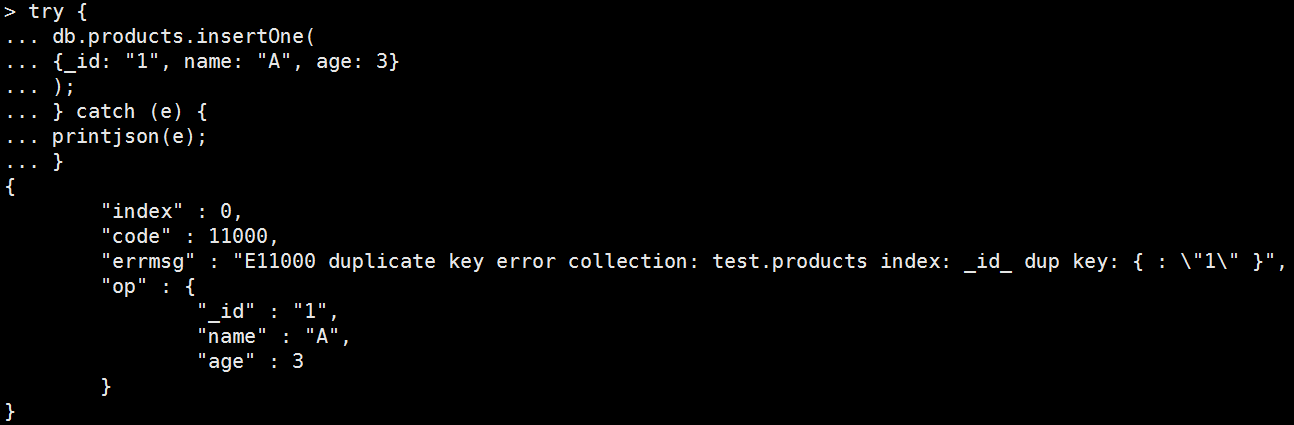
因此把上述修改成try-catch好啦~
Mongo Command |
|
try { db.products.insertOne( {_id: "1", name: "A", age: 3} ); } catch (e) { printjson(e); } |
執行結果:
|
Java Operate |
|
Document document = new Document("_id", "1") // .append("name", "A") // .append("age", 3); System.out.println(document.toJson()); try { collection.insertOne(document); } catch (MongoWriteException mwException) { int mwCode = mwException.getCode(); String errmsg = mwException.getMessage(); WriteError we = mwException.getError(); BsonDocument bsonDocument = we.getDetails(); System.out.println("code: " + mwCode); System.out.println("errmsg: " + errmsg); System.out.println("op: " + bsonDocument.toJson()); } System.out.println(document.toJson()); |
|
執行結果:
*由此可見MongoWriteException一樣可以取出跟commandline回傳一模一樣的訊息。 |
|

語法結構為:

是的,相信大家一定都注意到了,其實v3.2新增的insertOne跟insertMany這兩個方法就是將舊的insert拆分出來,並且這兩個新方法會拋出exception。個人猜想Mongo這樣做是為了更符合js寫作習慣跟簡化API操作的複雜度。
array的大小其實並沒有現在,但MongoDB會以1000為單位操作,也就是超過1000個元素它將會拆成兩個group進行寫入。
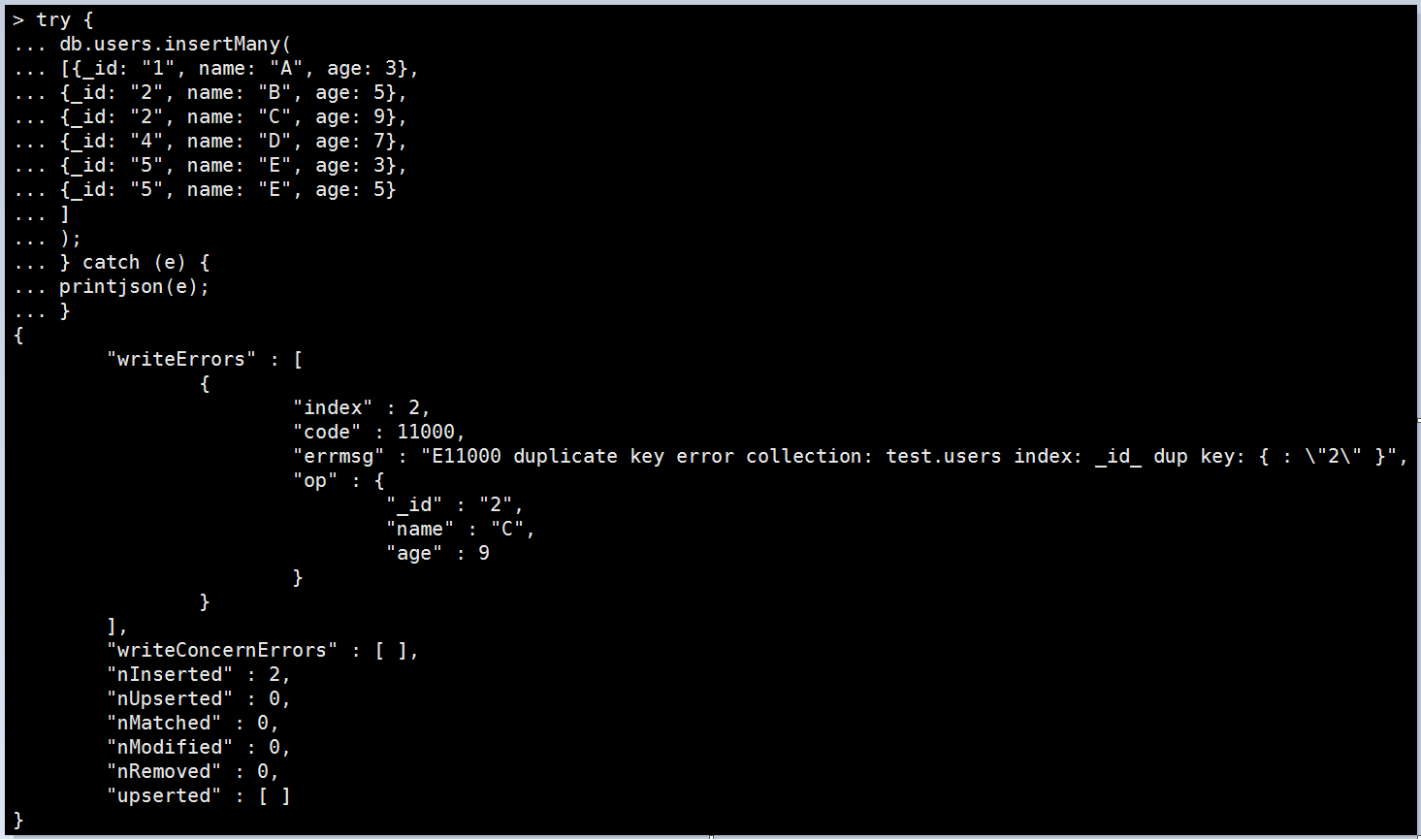
• insertMany的操作跟insertOne一樣,所以這裡只寫一個操作ordered:false的例子
Mongo Command |
|
try { db.users.insertMany( [ {_id: "1", name: "A", age: 3}, {_id: "2", name: "B", age: 5}, {_id: "2", name: "C", age: 9}, {_id: "4", name: "D", age: 7}, {_id: "5", name: "E", age: 3}, {_id: "5", name: "E", age: 5} ] ); } catch (e) { printjson(e); } |
執行結果:
|
Java Operate |
|
List<Document> documentList = new ArrayList<>(); documentList.add(new Document("_id", "1").append("name", "A").append("age", 3)); documentList.add(new Document("_id", "2").append("name", "B").append("age", 5)); documentList.add(new Document("_id", "2").append("name", "C").append("age", 9)); documentList.add(new Document("_id", "4").append("name", "D").append("age", 7)); documentList.add(new Document("_id", "5").append("name", "E").append("age", 3)); documentList.add(new Document("_id", "5").append("name", "E").append("age", 5)); documentList.forEach(System.out::println); // 1.8新增的forEach default method跟Lambda表示式 try { InsertManyOptions options = new InsertManyOptions().ordered(false); // 設定ordered:false collection.insertMany(documentList, options); } catch (MongoBulkWriteException mbwException) { int mbwCode = mbwException.getCode(); String errmsg = mbwException.getMessage(); List<BulkWriteError> we = mbwException.getWriteErrors(); BulkWriteResult writeResult = mbwException.getWriteResult(); int nInserted = writeResult.getInsertedCount(); System.out.println("code: " + mbwCode); System.out.println("errmsg: " + errmsg); System.out.println("nInserted: " + nInserted); we.forEach(eachBulkWriteError -> System.out.println("eachBWE: " + eachBulkWriteError)); } |
|
執行結果:
|
|
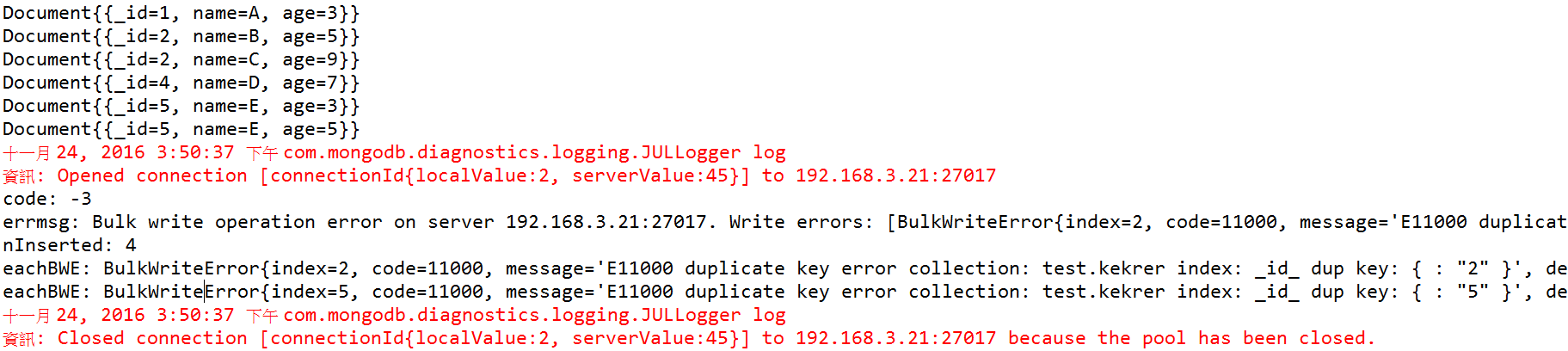
Mongo Command沒啥好說的了,所以我們來看Java Operate。在java裡想使用ordered:false的操作就在inseryMany第二個參數放入一個物件InsertManyOptions並設定為ordered:false就好囉,就跟commandline的操作一樣,很直覺吧?
所以今天只要有任何一個錯誤的時候,你就可以在exception裡執行爆炸後的處理,因此很直觀的從MongoBulkWriteException取出任何關於這次insert的訊息。等等,那寫入成功哩?我怎麼知道寫入成功哩,insertMany並沒有回傳值啊~~~

其實只要毫無反應的往下執行,就代表insert是全數正常的,不需要處理囉。
奇怪,阿不是還有一個writeConcern設定嗎?怎麼在java的insertMany的方法裡沒有看到哩?其實這東西是設定在MongoDatabase或MongoCollection上設定:
MongoDatabase db = mongoClient.getDatabase(this.dbName); db.withWriteConcern(writeConcern); MongoCollection<Document> collection = db.getCollection(this.collectionName); db.withWriteConcern(writeConcern); |
詳細操作方式將由後續的”MongoDB的WriteConcern”說明。
7. MongoDB CRUD之Read

• find事實上回傳的是一個cursor,因此可以接著套用cursor的操作。(像上圖的limit就是一個cursor的操作)
• 如果沒有用var 變數名稱來把這個cursor接起來做其他操作的話,Mongo會自動幫你顯示前20筆(也就是limit(20)),但可以透過DBQuery.shellBatchSize來調整。
語法結構:
db.collection.find(query, projection)
1.%2 寫入測試資料
db.users.insertMany([ {"_id":1,"name":"sue","age":19,"type":1,"status":"P","favorites":{"artist":"Picasso","food":"pizza"},"finished":[17,3],"badges":["blue","black"],"points":[{"points":85,"bonus":20},{"points":85,"bonus":10}]}, {"_id":2,"name":"bob","age":42,"type":1,"status":"A","favorites":{"artist":"Miro","food":"meringue"},"finished":[11,25],"badges":["green"],"points":[{"points":85,"bonus":20},{"points":64,"bonus":12}]}, {"_id":3,"name":"ahn","age":22,"type":2,"status":"A","favorites":{"artist":"Cassatt","food":"cake"},"finished":[6],"badges":["blue","red"],"points":[{"points":81,"bonus":8},{"points":55,"bonus":20}]}, {"_id":4,"name":"xi","age":34,"type":2,"status":"D","favorites":{"artist":"Chagall","food":"chocolate"},"finished":[5,11],"badges":["red","black"],"points":[{"points":53,"bonus":15},{"points":51,"bonus":15}]}, {"_id":5,"name":"xyz","age":23,"type":2,"status":"D","favorites":{"artist":"Noguchi","food":"nougat"},"finished":[14,6],"badges":["orange"],"points":[{"points":71,"bonus":20}]}, {"_id":6,"name":"abc","age":43,"type":1,"status":"A","favorites":{"food":"pizza","artist":"Picasso"},"finished":[18,12],"badges":["black","blue"],"points":[{"points":78,"bonus":8},{"points":57,"bonus":7}]} ]); |
查詢全部
Mongo Command |
db.users.find({}); 或者 db.users.find(); 執行結果:
|
Java Operate |
FindIterable<Document> findIterable = collection.find(); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


等於查詢
Mongo Command |
db.users.find( { status: "A" } ); 執行結果:
|
Java Operate |
Bson eq = Filters.eq("status", "A"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


嵌套查詢(Embedded Query)
Mongo Command |
db.users.find( {favorites: { artist: "Picasso", food: "pizza" }} ); 執行結果:
|
Java Operate |
Bson artist_eq_Picasso = Filters.eq("artist", "Picasso"); Bson food_eq_pizza = Filters.eq("food", "pizza"); Bson andFilter = Filters.and(artist_eq_Picasso, food_eq_pizza); Bson eq = Filters.eq("favorites", andFilter); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


使用點(dot)做嵌套查詢(Embedded Query)
Mongo Command |
db.users.find( { "favorites.artist": "Picasso" } ); 執行結果:
|
Java Operate |
Bson eq = Filters.eq("favorites.artist", "Picasso"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


使用查詢操作子(Query Operators )
比較操作子(Comparison)
$eq 等於 |
$gt 大於 |
$lt 小於 |
$in 任一值符合 |
$ne 不等於 |
$gte 大於等於 |
$lte 小於等於 |
$nin 多數值不符合 |
$eq 等於
Mongo Command |
|
db.users.find( {status:{$eq:"A"}} ); |
其實也就等於 db.users.find({status:"A"}); |
執行結果:
|
|
Java Operate |
|
Bson eq = Filters.eq("status", "A"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
|
執行結果:
|
|

$ne 不等於
Mongo Command |
db.users.find( {status:{$ne:"A"}} ); 執行結果:
|
Java Operate |
Bson eq = Filters.ne("status", "A"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$gt 大於
Mongo Command |
db.users.find( { age: {$gt:34} } ); 執行結果:
|
Java Operate |
Bson eq = Filters.gt("age", 34); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$gte 大於等於
Mongo Command |
db.users.find( { age: {$gte:34} } ); 執行結果:
|
Java Operate |
Bson eq = Filters.gte("age", 34); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$lt 小於
Mongo Command |
db.users.find( { age: {$lt:23} } ); 執行結果:
|
Java Operate |
Bson eq = Filters.lt("age", 23); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$lte 小於等於
Mongo Command |
db.users.find( { age: {$lte:23} } ); 執行結果:
|
Java Operate |
Bson eq = Filters.lte("age", 23); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$in 任一值符合
Mongo Command |
db.users.find( { status: {$in : ["D","P"] } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.in("status", "D", "P"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$nin 多數值不符合
Mongo Command |
db.users.find( { status: {$nin : ["D","P"] } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.nin("status", "D", "P"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


邏輯操作子(Logical)
Mongo Command |
db.users.find( { $or : [ { status: "A" }, { age: { $gt:34 } } ] } ); 執行結果:
|
Java Operate |
Bson eq = Filters.or(Filters.eq("status", "A"), Filters.gt("age", 34)); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


如同RDB一樣,若查詢的field有建立index,則會使用index查詢,若沒有index則會進行集合掃描!!而每個field都支援各自的index。
Mongo Command |
db.users.find( { $and : [ { status: "A" }, { age: { $gt:34 } } ] } ); 執行結果:
|
Java Operate |
Bson eq = Filters.and(Filters.eq("status", "A"), Filters.gt("age", 34)); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


Mongo Command |
db.users.find( { age: { $not: { $gt:34 } } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.not(Filters.gt("age", 34)); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


“大於的反向”並不等於”小於等於”,因為”大於的反向”同時還包含了沒有該field情況,考慮以下情況,寫入資料:
db.users.insertMany([ {"_id":7,"name":"ggg","type":1,"status":"E"}, {"_id":8,"name":"ggg","type":1,"status":"E"} ]); |
分別執行一次”小於等於”跟”大於的反向”來測試看看:
“小於等於” db.users.find( { age: { $lte: 34 } } );

“大於的反向”

You see~跑出了_id:7跟_id:8這兩筆資料。
Mongo Command |
db.users.find( { $nor : [ { status: "A" }, { age: { $gt:34 } } ] } ); 執行結果:
|
Java Operate |
Bson eq = Filters.nor(Filters.eq("status", "A"), Filters.gt("age", 34)); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|
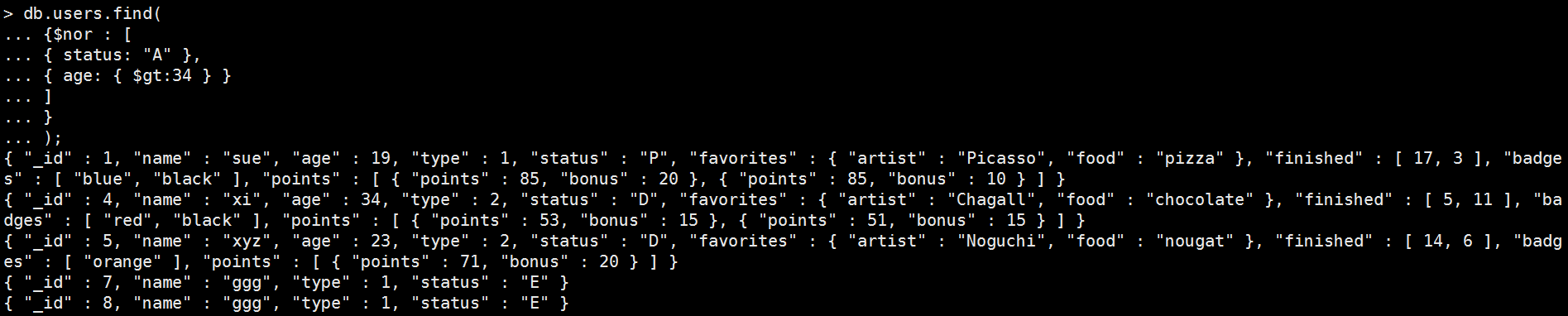

元素操作子(Element)
$exists 存在判斷 |
$type 型態判斷 |
$exists 存在判斷
判斷該field是否存在。
Mongo Command |
db.users.find( { favorites: { $exists:true } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.exists("favorites", false); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


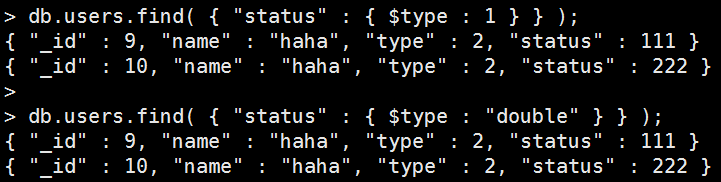
$type 型態判斷
判斷field的內容型態,所有型態請看官方清單 。
語法型態: { field: { $type: <BSON type number> | <String alias> } }
寫入資料:
db.users.insertMany([ { "_id" : 9, "name" : "haha", "type" : 2, "status" : 111 }, { "_id" : 10, "name" : "haha", "type" : 2, "status" : 222 } ]); |
Mongo Command |
db.users.find( { "status" : { $type : 1 } } ); 或者使用別名 db.users.find( { "status" : { $type : "double" } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.type("status", BsonType.DOUBLE); //Bson eq = Filters.type("status", "double"); // 或者使用別名 FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|

另外有”number”型態同時判斷double、int、long等數字型態。
Mongo Command |
db.users.find( { "status" : { $type : "number" } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.type("status", "number"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|

評估查詢子(Evaluation)
$mod 餘數判斷 |
$regex 正規表達式判斷 |
$text 文本搜尋 |
$where js語法判斷 |
$mod 餘數判斷
Mongo Command |
db.users.find( { age: { $mod: [2,0] } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.mod("age", 2, 0); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


*只會針對數字處理,只要是非數字的內容都會略過,不找出來。
$regex 正規表達式判斷
顧名思義,就是用regular expression來找資料。採用PCRE(Perl compatible regular expressions)v8.39。語法結構:
{ <field>: { $regex: /pattern/, $options: '<options>' } }
{ <field>: { $regex: 'pattern', $options: '<options>' } }
{ <field>: { $regex: /pattern/<options> } }
可以簡化為:
{ <field>: /pattern/<options> }
<options>為可選項目,共有以下幾項可以選擇:
i |
忽略大小寫 |
|
m |
考慮到換行符號,因此可用來改變^跟$比對的位置。 正常來說^跟$是判斷此一字串頭尾,但如果中間有換行符號,對於我們邏輯上來說是要各自判斷的,則可以使用此符號。 |
|
x |
忽略所有空白,且跳過#開頭的註解然後匹配到換行符號之前。 |
不可使用簡化寫法。 |
s |
忽略\n。 |
不可使用簡化寫法。 |
寫入測試資料:
db.users.insertMany( [ { "_id" : 100, "name" : "abc123", "description" : "Single line description." } ,{ "_id" : 101, "name" : "abc789", "description" : "First line\nSecond line" } ,{ "_id" : 102, "name" : "xyz456", "description" : "Many spaces before line" } ,{ "_id" : 103, "name" : "xyz789", "description" : "Multiple\nline description" } ]); |
<options> i:
Mongo Command |
db.users.find( { name: { $regex: /^ABC/i } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.regex("name", "^ABC", "i"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


<options> m:
Mongo Command |
db. users.find( { description: { $regex: /^S/m } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.regex("description", "^S", "m"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


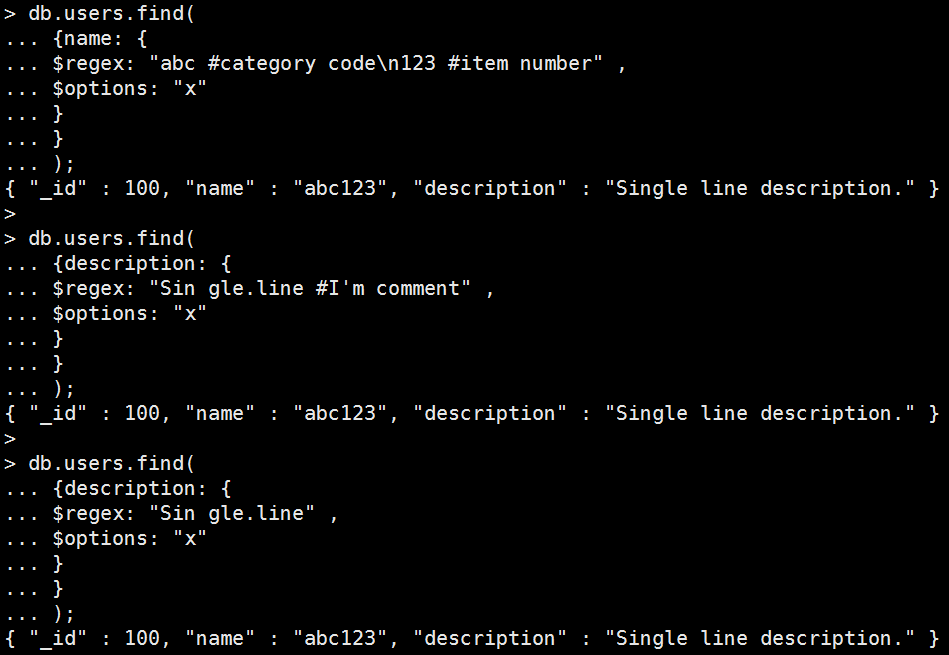
<options> x:
Mongo Command |
db.users.find( { name: { $regex: "abc #category code\n123 #item number" , $options: "x" } } ); db.users.find( { description: { $regex: "Sin gle.line #I'm comment" , $options: "x" } } ); db.users.find( { description: { $regex: "Sin gle.line" , $options: "x" } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson eq1 = Filters.regex("name", "abc #category code\n123 #item number", "x"); FindIterable<Document> findIterable1 = collection.find(eq1); findIterable1.forEach(showEach); Bson eq2 = Filters.regex("description", "Sin gle.line #I'm comment", "x"); FindIterable<Document> findIterable2 = collection.find(eq2); findIterable2.forEach(showEach); Bson eq3 = Filters.regex("description", "Sin gle.line", "x"); FindIterable<Document> findIterable3 = collection.find(eq3); findIterable3.forEach(showEach); |
執行結果:
|

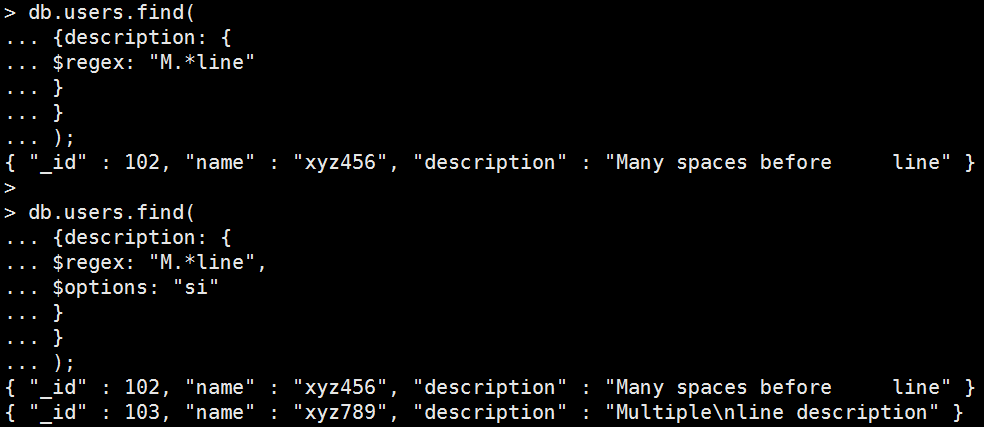
<options> s:
Mongo Command |
db.users.find( { description: { $regex: "M.*line" } } ); db.users.find( { description: { $regex: "M.*line", $options: "si" } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson eq1 = Filters.regex("description", "M.*line"); FindIterable<Document> findIterable1 = collection.find(eq1); findIterable1.forEach(showEach); Bson eq2 = Filters.regex("description", "M.*line", "si"); FindIterable<Document> findIterable2 = collection.find(eq2); findIterable2.forEach(showEach); |
執行結果:
|

在field有建index的情況下,regex是匹配大小寫時將會針對index裡的值比對,其速度將快於集合掃描。若regex是匹配開始(也就是^),MongoDB將會進一步優化速度,但”/^a/”,”/^a.*/”,”/^a.*$/”仍存在效能上的差異,”/^a/”速度將優於後兩者。
$text 文本搜尋
可以針對有建立text index 的field進行全文檢索。語法結構:
{
$text: {
$search: <string>,
$language: <string>,
$caseSensitive: <boolean>,
$diacriticSensitive: <boolean>
}
}
必要。提供or的搜尋字串或排除特定字串搜尋。 |
|
檢索語言 。 |
|
(預設false) |
就是不區分大小寫。 V3.2新功能 |
不區分é,ê,和 ë這種變音符號。 |
寫入測試資料:
db.articles.insert( [ { _id: 1, subject: "coffee", author: "xyz", views: 50 }, { _id: 2, subject: "Coffee Shopping", author: "efg", views: 5 }, { _id: 3, subject: "Baking a cake", author: "abc", views: 90 }, { _id: 4, subject: "baking", author: "xyz", views: 100 }, { _id: 5, subject: "Café Con Leche", author: "abc", views: 200 }, { _id: 6, subject: "Сырники", author: "jkl", views: 80 }, { _id: 7, subject: "coffee and cream", author: "efg", views: 10 }, { _id: 8, subject: "Cafe con Leche", author: "xyz", views: 10 } ] ) |
建立text index:
db.articles.createIndex( { subject: "text" } ) |
• 搜尋單字串
Mongo Command |
db.articles.find( { $text: { $search: "coffee" } } ) 執行結果:
|
Java Operate |
Bson eq = Filters.text("coffee"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 搜尋多字串
Mongo Command |
db.articles.find( { $text: { $search: "bake coffee cake" } } ) 執行結果:
|
Java Operate |
Bson eq = Filters.text("bake coffee cake"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 完整字串搜尋
Mongo Command |
db.articles.find( { $text: { $search: "\"coffee shop\"" } } ) 執行結果:
|
Java Operate |
Bson eq = Filters.text("\"coffee shop\""); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 排除字串搜尋
Mongo Command |
db.articles.find( { $text: { $search: "coffee -shop" } } ) 執行結果:
|
Java Operate |
Bson eq = Filters.text("coffee -shop"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 敏感搜尋($caseSensitive:true)。
Mongo Command |
db.articles.find( { $text: { $search: "Coffee -shop", $caseSensitive: true } } ) 執行結果:
|
Java Operate |
TextSearchOptions textSearchOptions = new TextSearchOptions(); textSearchOptions.caseSensitive(true); Bson eq = Filters.text("Coffee -shop", textSearchOptions); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


$where js語法判斷
簡單來說就是可以丟javascript一個function過去執行,很~強~大~對吧!!
在function裡面可以使用this或obj來表示當下的document,藉此取用value來做運算。至於還有那些公開使用的properties或function請看官網說明 。
• Use case1
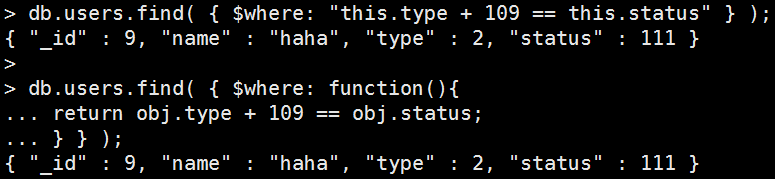
Mongo Command |
db.users.find( { $where: "this.type + 109 == this.status" } ); 或者 db.users.find( { $where: function(){ return obj.type + 109 == obj.status; } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.where("this.type + 109 == this.status"); //Bson eq = Filters.where("function() { return this.type + 109 == this.status; }"); // 或者 FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|

• Use case2
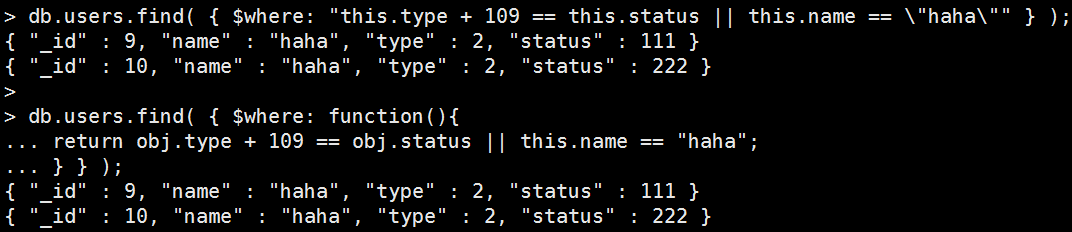
Mongo Command |
db.users.find( { $where: "this.type + 109 == this.status || this.name == \"haha\"" } ); 或者 db.users.find( { $where: function(){ return obj.type + 109 == obj.status || this.name == "haha"; } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.where("this.type + 109 == this.status || this.name == \"haha\""); //Bson eq = Filters.where("function() { return this.type + 109 == this.status || this.name == \"haha\"; }"); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); |
執行結果:
|

Array查詢子
寫入資料:
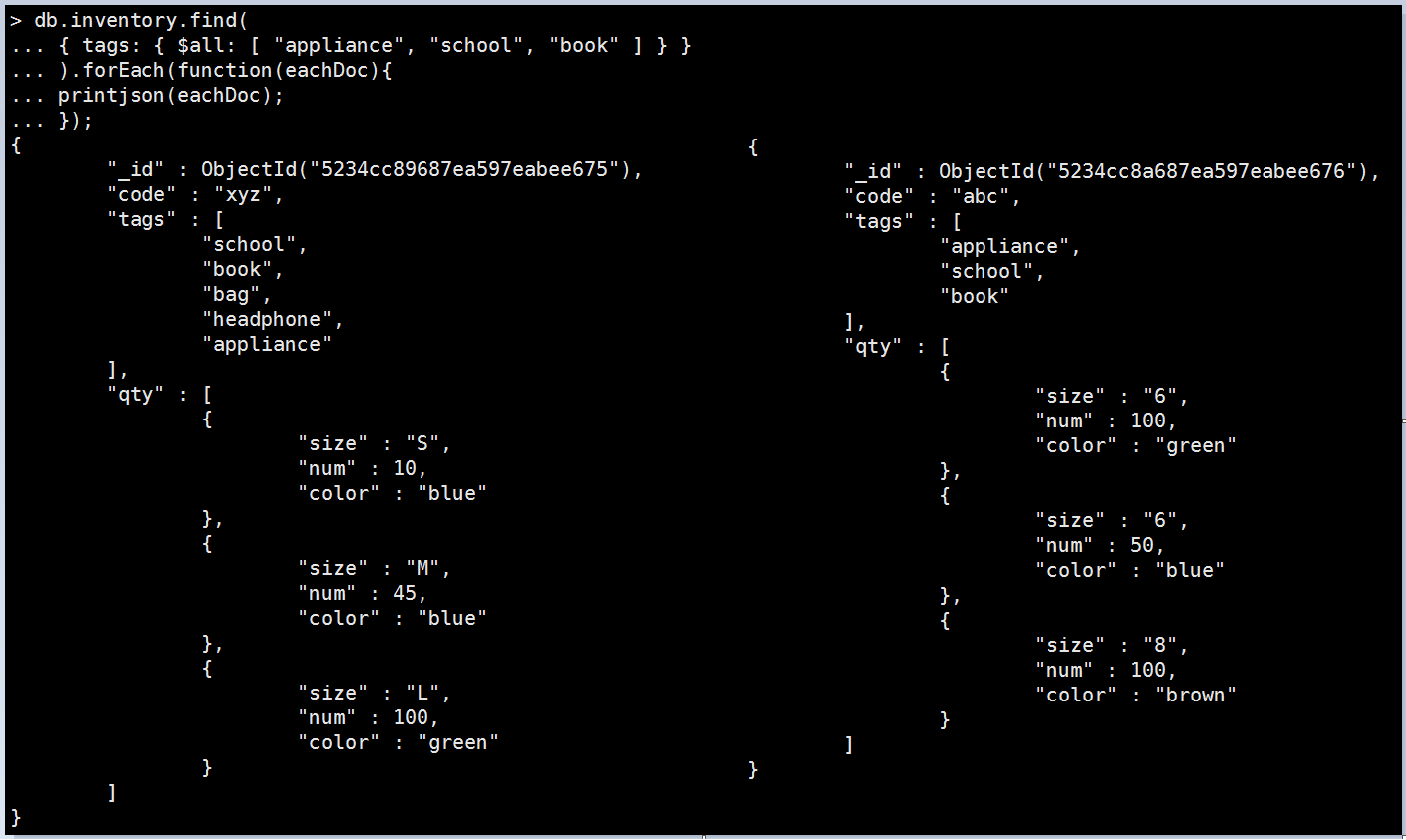
db.inventory.insertMany([ { _id: ObjectId("5234cc89687ea597eabee675"), code: "xyz", tags: [ "school", "book", "bag", "headphone", "appliance" ], qty: [ { size: "S", num: 10, color: "blue" }, { size: "M", num: 45, color: "blue" }, { size: "L", num: 100, color: "green" } ] }, { _id: ObjectId("5234cc8a687ea597eabee676"), code: "abc", tags: [ "appliance", "school", "book" ], qty: [ { size: "6", num: 100, color: "green" }, { size: "6", num: 50, color: "blue" }, { size: "8", num: 100, color: "brown" } ] }, { _id: ObjectId("5234ccb7687ea597eabee677"), code: "efg", tags: [ "school", "book" ], qty: [ { size: "S", num: 10, color: "blue" }, { size: "M", num: 100, color: "blue" }, { size: "L", num: 100, color: "green" } ] }, { _id: ObjectId("52350353b2eff1353b349de9"), code: "ijk", tags: [ "electronics", "school" ], qty: [ { size: "M", num: 100, color: "green" } ] } ]); |
弱符合
意思就是只要有出現要求的元素就好,有多的不管它。
Mongo Command |
db.inventory.find( { tags: { $all: [ "appliance", "school", "book" ] } } ).forEach(function(eachDoc){ printjson(eachDoc); }); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson filter = Filters.all("tags", "appliance", "school", "book"); FindIterable<Document> findIterable = collection.find(filter); findIterable.forEach(showEach); |
執行結果:
|

強符合
除了符合的元素外,有多的也不行。
Mongo Command |
db.inventory.find( { tags: [ "appliance", "school", "book" ] } ).forEach(function(eachDoc){ printjson(eachDoc); }); 或者使用” { $and: [ { tags: [ "appliance", "school", "book" ] } ] }”,結果是相同的。 執行結果: |
Java Operate |
Block<Document> showEach = document -> System.out.println(document); List<BsonString> BsonArrayList = new ArrayList<>(); BsonArrayList.add(new BsonString("appliance")); BsonArrayList.add(new BsonString("school")); BsonArrayList.add(new BsonString("book")); Bson filter = new BsonDocument("tags", new BsonArray(BsonArrayList)); FindIterable<Document> findIterable = collection.find(filter); findIterable.forEach(showEach); |
執行結果:
此寫法是我try出來的,因為爬不到文章在說明這種操作。於是我思考了MongoDB操作概念全部都是JSON,因此我從這個角度出發try出了這個寫法,非常不高明,但也是我目前所能找到的寫法了,待高手提出更簡潔的寫法。 |

如果沒有使用$elemMatch來表明要針對每一個元素符合查詢條件時,在array底下會搜索個元素組合或單一元素內的組合。
針對各個元素搜尋。寫入資料:
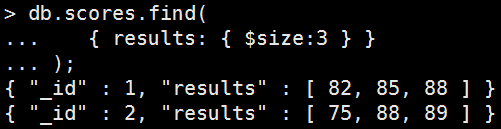
db.scores.insertMany( [ { _id: 1, results: [ 82, 85, 88 ] }, { _id: 2, results: [ 75, 88, 89 ] } ] ); |
Mongo Command |
db.scores.find( { results: { $elemMatch: { $gte: 80, $lt: 85 } } } ) 執行結果:
|
Java Operate |
找不到在java driver底下如何操作$element… |

找array的size。
Mongo Command |
db.scores.find( { results: { $size:3 } } ); 執行結果:
|
Java Operate |
Bson eq = Filters.size("results", 3); FindIterable<Document> findIterable = collection.find(eq); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|

返回array裡找到符合的第一個元素
Mongo Command |
db.inventory.find( { code: { $exists: true }, "qty.num": { $gte: 45 } }, { "qty.$": 1 } ); 執行結果:
|
Java Operate |
Bson f1 = Filters.exists("code"); Bson f2 = Filters.gte("qty.num", 45); Bson filter = Filters.and(f1, f2); FindIterable<Document> findIterable = collection.find(filter); findIterable.forEach(showEach); |
執行結果:
|


*特別注意,使用$取用的話,該field必須要下條件,才有辦法找到所謂的”第一個”元素。
控制返回array的數量,寫入測試資料:
db.test.insertMany( [ {_id:1, a:[10,11,12,13,14,15,16,17,18,19]}, {_id:2, a:[20,21,22,23,24,25,26,27,28,29]}, {_id:3, a:[30,31,32,33,34,35,36,37,38,39]}, {_id:4, a:[40,41,42,43,44,45,46,47,48,49]} ] ); |
返回前X個元素
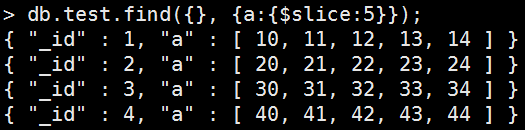
Example:返回前5個元素
Mongo Command |
db.test.find( {}, { a: { $slice: 5 } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson projection = Projections.slice("a", 5); FindIterable<Document> findIterable = collection.find().projection(projection); findIterable.forEach(showEach); |
執行結果:
|

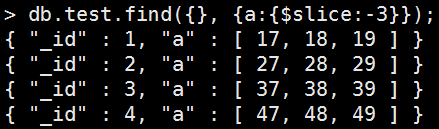
返回後X個元素
Example:返回後3個元素
Mongo Command |
db.test.find( {}, { a: { $slice: -3 } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson projection = Projections.slice("a", -3); FindIterable<Document> findIterable = collection.find().projection(projection); findIterable.forEach(showEach); |
執行結果:
|

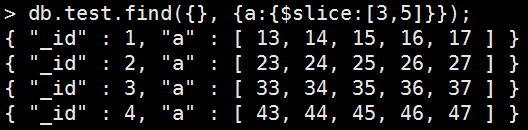
略過Y個元素然後返為X個元素
Example:略過前3個元素,從第4個元素開始,返回5個元素
Mongo Command |
db.test.find( {}, { a: { $slice: [3,5] } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson projection = Projections.slice("a", 3, 5); FindIterable<Document> findIterable = collection.find().projection(projection); findIterable.forEach(showEach); |
執行結果:
|

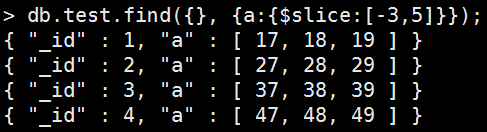
倒數Y個元素然後返回X個元素
Example:從倒數第3個元素開始(包含),返回5個元素
Mongo Command |
db.test.find( {}, { a: { $slice: [-3,5] } } ); 執行結果:
|
Java Operate |
Block<Document> showEach = document -> System.out.println(document); Bson projection = Projections.slice("a", -3, 5); FindIterable<Document> findIterable = collection.find().projection(projection); findIterable.forEach(showEach); |
執行結果:
|

$and與$or複合查詢
Mongo Command |
db.users.find( { status: "A", $or: [ { age: { $lt: 30 } }, { type: 1 } ] } ); 執行結果:
|
Java Operate |
Bson f1 = Filters.lt("age", 30); Bson f2 = Filters.eq("type", 1); Bson f3 = Filters.or(f1, f2); Bson f4 = Filters.eq("status", "A"); Bson filter = Filters.and(f3, f4); FindIterable<Document> findIterable = collection.find(filter); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


Array組合式查詢
Mongo Command |
db.users.find( { finished: { $gt: 15, $lt: 20 } } ); 執行結果:
|
Java Operate |
Bson f1 = Filters.gt("finished", 15); Bson f2 = Filters.lt("finished", 20); Bson filter = Filters.and(f1, f2); FindIterable<Document> findIterable = collection.find(filter); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


此查詢為”找有元素大於15且別的元素小於20的資料”。
[17,3] |
V |
17大於15且3小於20 |
[11,25] |
V |
11小於20且25大於15 |
[18,12] |
V |
18大於15且12小於20 |
[6] |
X |
6小於20,但沒有別的元素大於15 |
[5,11] |
X |
5跟11都小於20,但沒有別的元素大於15 |
[14,6] |
X |
14跟6都小於20,但沒有別的元素大於15 |
Array絕對位置嵌套查詢
Mongo Command |
db.users.find( { 'points.0.points': { $lte: 55 } } ); 執行結果:
|
Java Operate |
Bson filter = Filters.lte("points.0.points", 55); FindIterable<Document> findIterable = collection.find(filter); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


Array元素間組合查詢
Mongo Command |
db.users.find( { "points.points": { $lte: 70 }, "points.bonus": 20 } ); 執行結果:
|
Java Operate |
Bson f1 = Filters.lte("points.points", 70); Bson f2 = Filters.eq("points.bonus", 20); Bson filter = Filters.and(f1, f2); FindIterable<Document> findIterable = collection.find(filter); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


取值操作子(Projection Operators)
簡單來說就是SQL的select column的功能,讓你選擇要回傳什麼內容。語法結構。
• Value=1時,表示包含該field回傳
• Value=0時,表示排除該field回傳
• 1與0無法混用,一個projection裡只能同時只有1或同時只有0。概念應該是如果用1的話就像是一個空集合{}往裡面塞東西;0的話就是原本的集合{…}一直拿掉東西。
• *_id總是會回傳,也唯獨它可以混用_id:0來排除回傳。
• 指定回傳field
Mongo Command |
|
db.users.find( { status: "A" }, { name: 1, status: 1 } ); |
執行結果:
|
Java Operate |
|
Bson filter = Filters.eq("status", "A"); Bson projection = Filters.and(Filters.eq("name", 1), Filters.eq("status", 1)); FindIterable<Document> findIterable = collection.find(filter).projection(projection); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
|
執行結果:
|
|
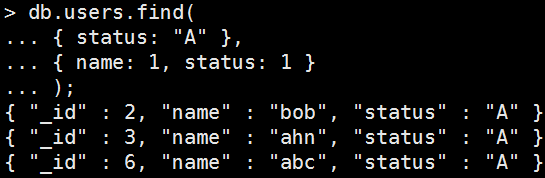

• 回傳指定field並剔除_id
Mongo Command |
|
db.users.find( { status: "A" }, { name: 1, status: 1, _id: 0 } ); |
執行結果:
|
Java Operate |
|
Bson filter = Filters.eq("status", "A"); Bson projection = Filters.and(Filters.eq("name", 1), Filters.eq("status", 1), Filters.eq("_id", 0)); FindIterable<Document> findIterable = collection.find(filter).projection(projection); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
|
執行結果:
|
|
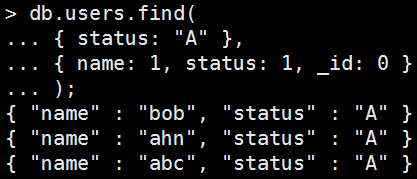

• 回傳全部但剃除指定項目
Mongo Command |
db.users.find( { status: "A" }, { favorites: 0, points: 0 } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("status", "A"); Bson projection = Filters.and(Filters.eq("favorites", 0), Filters.eq("points", 0)); FindIterable<Document> findIterable = collection.find(filter).projection(projection); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 指定回傳嵌套(Embedded)內容
Mongo Command |
db.users.find( { status: "A" }, { name: 1, status: 1, "favorites.food": 1 } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("status", "A"); Bson projection = Filters.and(Filters.eq("name", 1), Filters.eq("status", 1), Filters.eq("favorites.food", 1)); FindIterable<Document> findIterable = collection.find(filter).projection(projection); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


• 指定回傳巢狀內容為array時的取法
Mongo Command |
db.users.find( { status: "A" }, { name: 1, status: 1, "points.bonus": 1 } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("status", "A"); Bson projection = Filters.and(Filters.eq("name", 1), Filters.eq("status", 1), Filters.eq("points.bonus", 1)); FindIterable<Document> findIterable = collection.find(filter).projection(projection); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
執行結果:
|


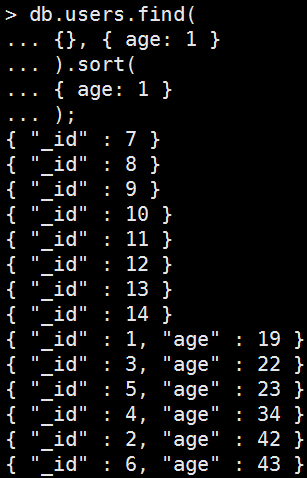
排序
1:為昇冪排序;-1為降冪排序。
Mongo Command |
|
db.users.find( {}, { age: 1 } ).sort( { age: 1 } ); |
執行結果:
|
Java Operate |
|
Bson projection = Filters.and(Filters.eq("age", 1)); Bson sort = Sorts.ascending("age"); FindIterable<Document> findIterable = collection.find().projection(projection).sort(sort); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
|
執行結果:
|
|
分頁
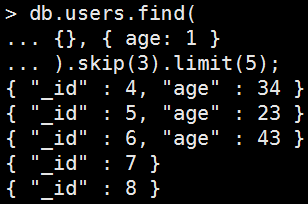
必須使用skip跟limit來達成。
Mongo Command |
|
db.users.find( {}, { age: 1 } ).skip(3).limit(5); |
執行結果:
|
Java Operate |
|
Bson projection = Filters.and(Filters.eq("age", 1)); FindIterable<Document> findIterable = collection.find().projection(projection).skip(3).limit(5); Block<Document> showEach = document -> System.out.println(document); findIterable.forEach(showEach); |
|
執行結果:
|
|

小結一下
• ”使用點(dot)做嵌套查詢”與”嵌套查詢”是存在差異性的。試著查詢” db.users.find({favorites:{artist:"Picasso"}});”跟” db.users.find({"favorites.artist":"Picasso" });”。在直覺上它應該要得到一樣的結果,但你會發現它找不到資料。那是因為” 使用點(dot)做嵌套查詢”是單一符合即可,而”嵌套查詢”它必須是完整符合所有條件。
• $in跟$or都可以達到相同目的,但官方表示使用$in效率來的比$or來的好。
• 型態清單 裡的MinKey跟MaxKey是一種特殊形態,不管跟什麼其他型態一起比,它們就是最小跟最大。通常是用在shard key上,但官方的sample 拿來使用在數值裡,是比較奇怪的情況,但也沒有說不行這樣塞資料。
• 隨時要有「如果這個field是null或根本missing時會怎麼樣」的想法,就像寫java一樣要意識到null一樣。
8. MongoDB CRUD之Update
update有三種方法:
B. db.collection. update One() New in version 3.2
C. db.collection. update Many() New in version 3.2
語法結構:

Parameter |
Type (R:required) |
Default |
Description |
query |
document (R) |
V3.0之後,若upsert:true,只會更新存在的document,不會insert新的document了。 |
|
update |
document (R) |
要更新的內容 |
|
upsert |
Boolean |
false |
true:找不到要更新的內容時會insert documnet false:找不到更新內容不會inser codument |
multi |
Boolean |
false |
true:更新所有匹配query的document false:只會更新第一個找到的document |
writeConcern |
document |
請參閱Mongo Read裡的writeConcern |
更新
寫入測試資料:
db.books.insertMany(
[ {
_id: 1,
item: "TBD",
stock: 1,
info: { publisher: "1111", pages: 430 },
tags: [ "technology", "computer" ],
ratings: [ { by: "ijk", rating: 4 }, { by: "lmn", rating: 5 } ],
reorder: false
}
]
);
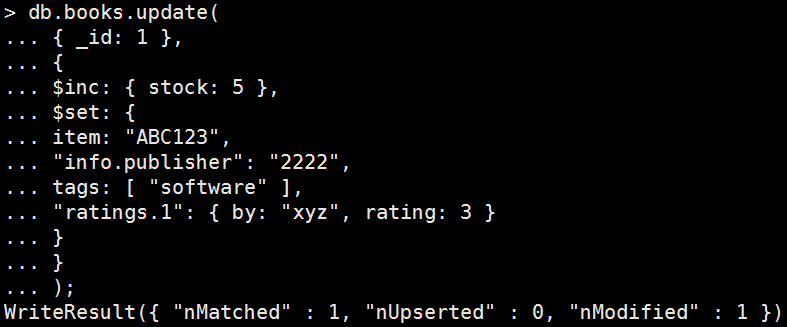
Mongo Command |
db.books.update( { _id: 1 }, { $inc: { stock: 5 }, $set: { item: "ABC123", "info.publisher": "2222", tags: [ "software" ], "ratings.1": { by: "xyz", rating: 3 } } } ); 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |
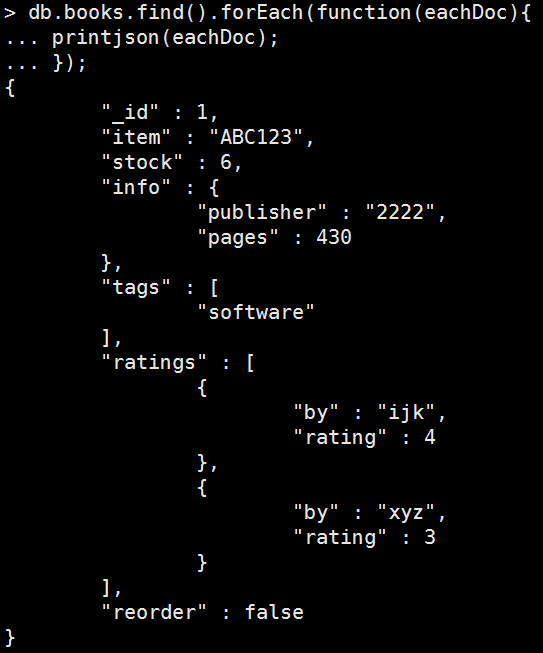
查看一次資料:
移除field
Mongo Command |
db.books.update( { _id: 1 }, { $unset: { tags: 1 } } ); 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |

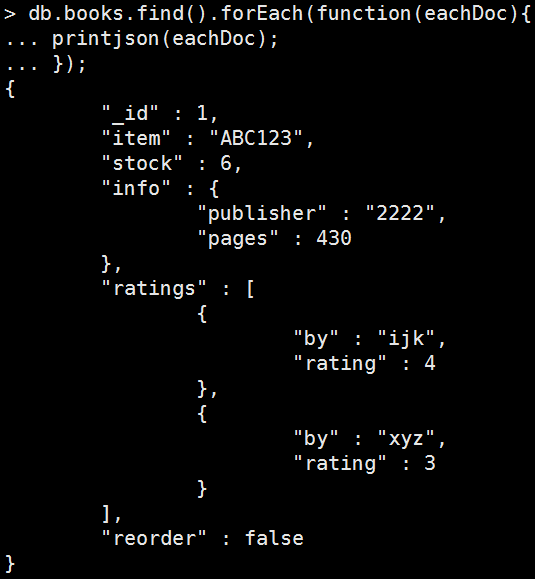
查看一下資料
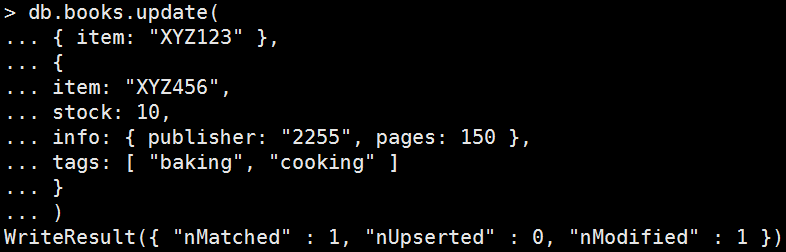
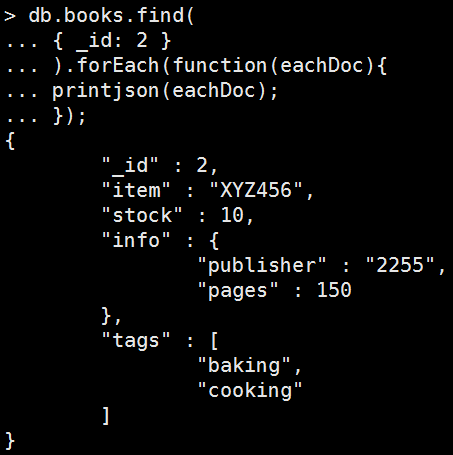
Replace All
寫入資料:
db.books.insertMany(
[ {
_id: 2,
item: "XYZ123",
stock: 15,
info: { publisher: "5555", pages: 150 },
tags: [ ],
ratings: [ { by: "xyz", rating: 5, comment: "ratings and reorder will go away after update"} ],
reorder: false
}
]
);
Mongo Command |
db.books.update( { item: "XYZ123" }, { item: "XYZ456", stock: 10, info: { publisher: "2255", pages: 150 }, tags: [ "baking", "cooking" ] } ) 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |
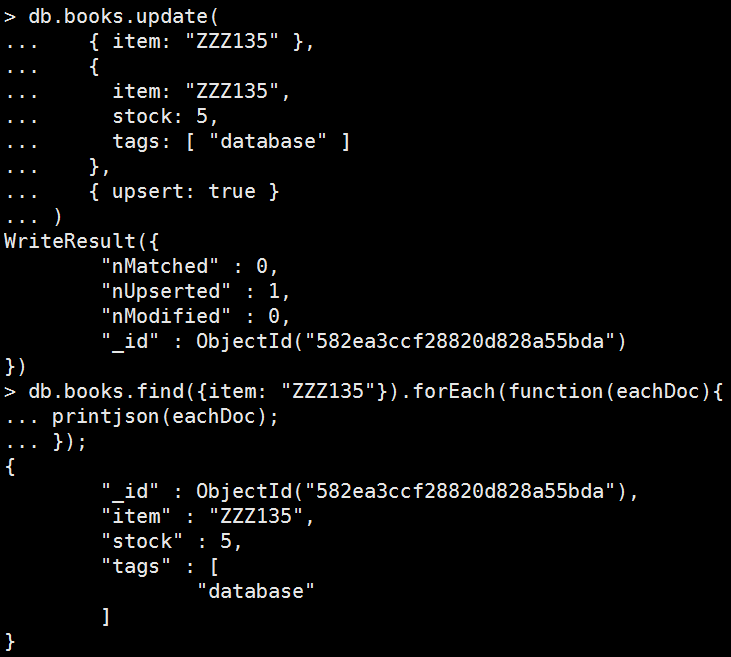
更新不匹配寫入
Mongo Command |
db.books.update( { item: "ZZZ135" }, { item: "ZZZ135", stock: 5, tags: [ "database" ] }, { upsert: true } ) 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |
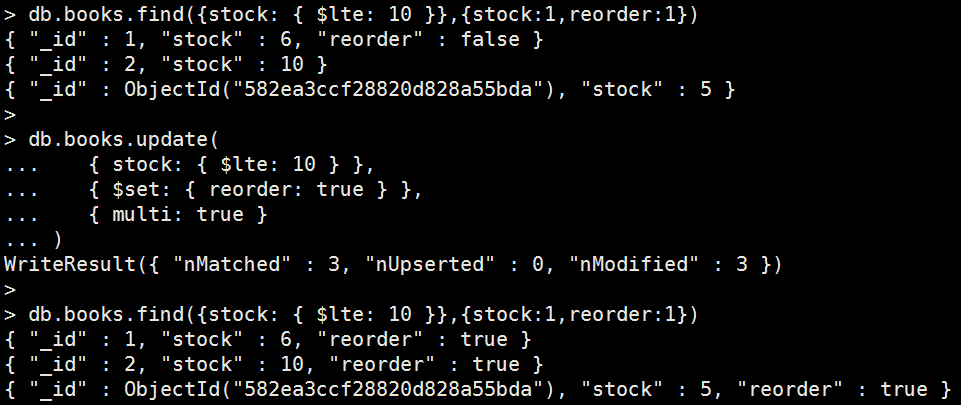
多筆更新
Mongo Command |
db.books.update( { stock: { $lte: 10 } }, { $set: { reorder: true } }, { multi: true } ); 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |
同時使用upsert跟multi
寫入資料:
db.books.insertMany(
[ {
_id: 5,
item: "EFG222",
stock: 18,
info: { publisher: "0000", pages: 70 },
reorder: true
},
{
_id: 6,
item: "EFG222",
stock: 15,
info: { publisher: "1111", pages: 72 },
reorder: true
}
]
);
Mongo Command |
db.books.update( { item: "EFG222" }, { $set: { reorder: false, tags: [ "literature", "translated" ] } }, { upsert: true, multi: true } ); 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |

如果找不到資料,將會混和<query>跟<update> inser一筆新資料如下:
db.books.update(
{ item: "KERKER" },
{ $set: { reorder: false, tags: [ "literature", "translated" ] } },
{ upsert: true, multi: true }
);
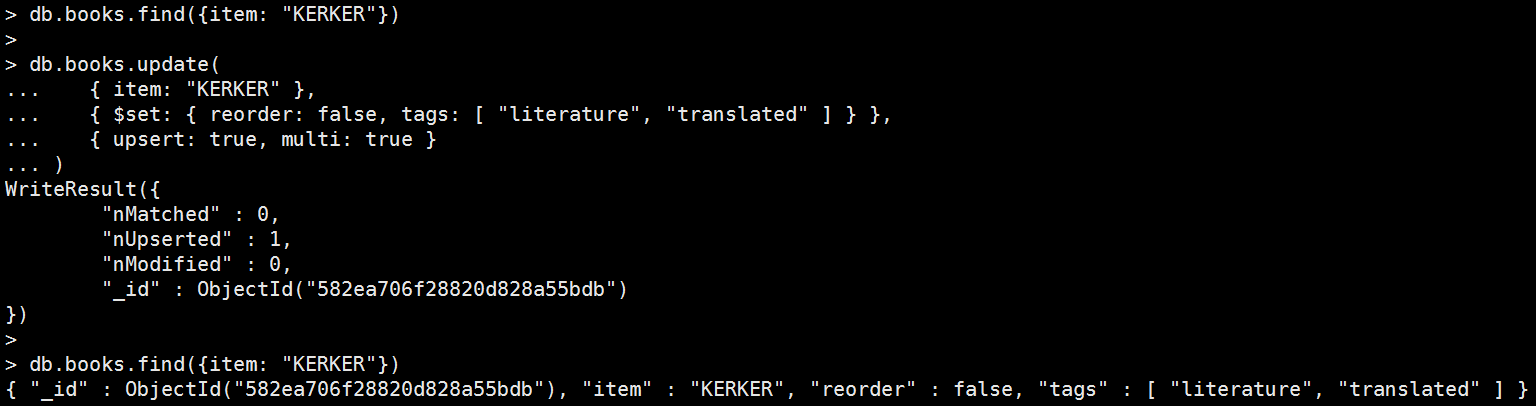
語法結構:

寫入資料:
db.restaurant.insertMany(
[ { "_id" : 1, "name" : "Central Perk Cafe", "Borough" : "Manhattan" },
{ "_id" : 2, "name" : "Rock A Feller Bar and Grill", "Borough" : "Queens", "violations" : 2 },
{ "_id" : 3, "name" : "Empire State Pub", "Borough" : "Brooklyn", "violations" : 0 }
]
);
Mongo Command |
db.restaurant.updateOne( { "name" : "Central Perk Cafe" }, { $set: { "violations" : 3 } } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("name", "Central Perk Cafe"); Bson update = Updates.set("violations", 3); UpdateResult updateResult = collection.updateOne(filter, update); System.out.println(updateResult); |
執行結果:
|
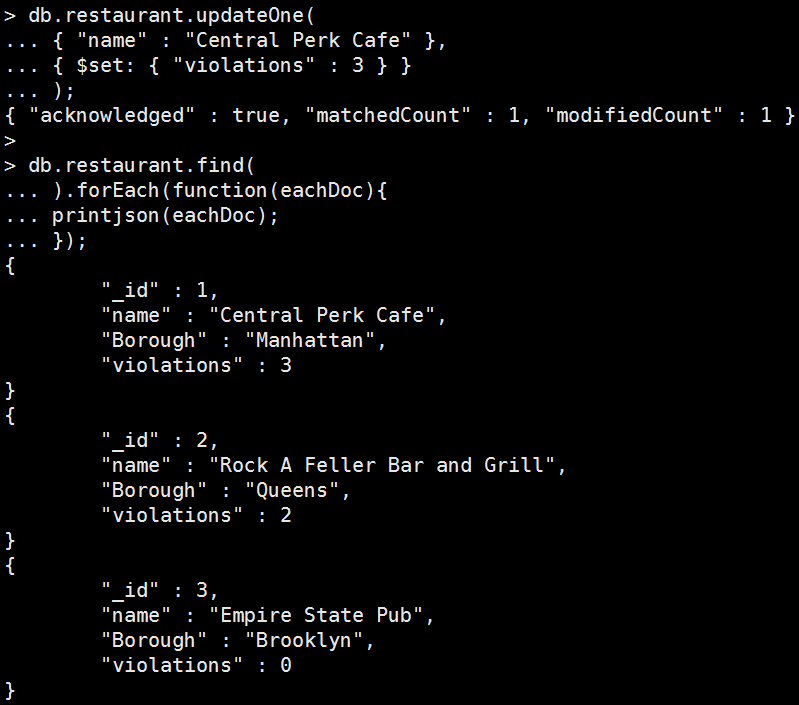

如果在執行一次,

modifiedCount會顯示0是因為原始資料跟要修改一樣,所以訊息才會是match:1但modify:0
語法結構:

其實它的行為跟updateOne一樣,這邊不再多述。
9. MongoDB CRUD之Delete
delete有三種方法:
B. db.collection. delete One() New in version 3.2
C. db.collection. delete Many() New in version 3.2
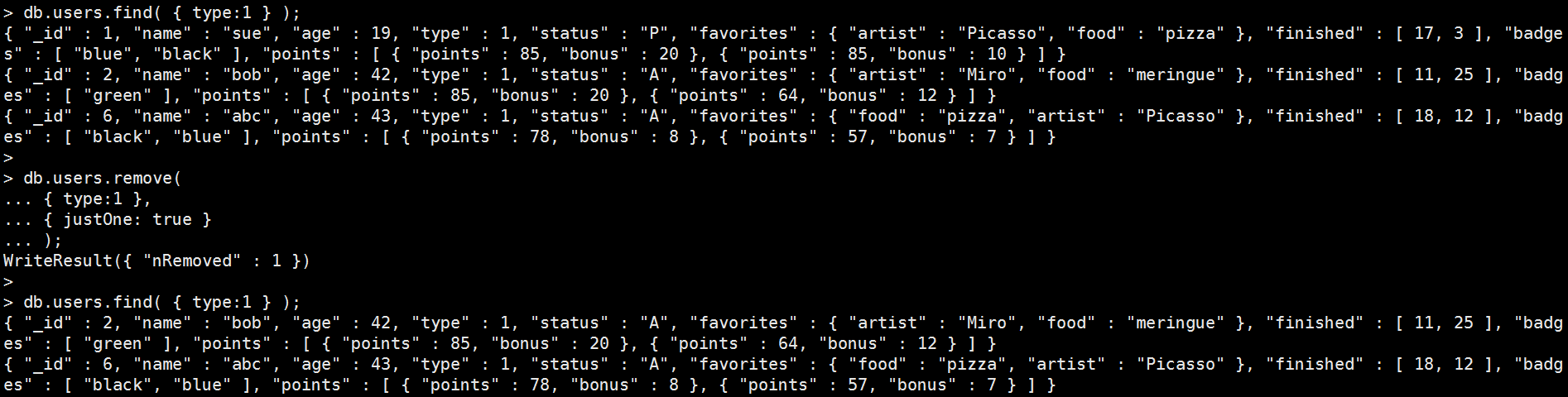
寫入資料:
db.users.insertMany( [ {"_id":1,"name":"sue","age":19,"type":1,"status":"P","favorites":{"artist":"Picasso","food":"pizza"},"finished":[17,3],"badges":["blue","black"],"points":[{"points":85,"bonus":20},{"points":85,"bonus":10}]}, {"_id":2,"name":"bob","age":42,"type":1,"status":"A","favorites":{"artist":"Miro","food":"meringue"},"finished":[11,25],"badges":["green"],"points":[{"points":85,"bonus":20},{"points":64,"bonus":12}]}, {"_id":3,"name":"ahn","age":22,"type":2,"status":"A","favorites":{"artist":"Cassatt","food":"cake"},"finished":[6],"badges":["blue","red"],"points":[{"points":81,"bonus":8},{"points":55,"bonus":20}]}, {"_id":4,"name":"xi","age":34,"type":2,"status":"D","favorites":{"artist":"Chagall","food":"chocolate"},"finished":[5,11],"badges":["red","black"],"points":[{"points":53,"bonus":15},{"points":51,"bonus":15}]}, {"_id":5,"name":"xyz","age":23,"type":2,"status":"D","favorites":{"artist":"Noguchi","food":"nougat"},"finished":[14,6],"badges":["orange"],"points":[{"points":71,"bonus":20}]}, {"_id":6,"name":"abc","age":43,"type":1,"status":"A","favorites":{"food":"pizza","artist":"Picasso"},"finished":[18,12],"badges":["black","blue"],"points":[{"points":78,"bonus":8},{"points":57,"bonus":7}]} ] ); |
語法結構:

<justOne>可以設定為1或true,就是只會刪除找到的第一筆。
Mongo Command |
db.users.remove( { type:1 }, { justOne: true } ); 執行結果:
|
Java Operate |
v3.3.0的driver捨棄了這個舊的方法,所以已經看不到update這個方法了。 |
語法結構:
Mongo Command |
db.users.deleteOne( { type:1 } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("type", 1); DeleteResult deleteResult = collection.deleteOne(filter); System.out.println(deleteResult); |
執行結果:
|


語法結構:

Mongo Command |
db.users.deleteMany( { type:2 } ); 執行結果:
|
Java Operate |
Bson filter = Filters.eq("type", 2); DeleteResult deleteResult = collection.deleteMany(filter); System.out.println(deleteResult); |
執行結果:
|


10. MongoDB的WriteConcern
語法結構:

寫入關注為MongoDB對於寫入的處理方式(standalone、replica sets、sharded clusters),在sharded clusters下會pass給別台。例如在sharded clusters裡,user可以設定必須要寫入兩台、三台sharded才可以response或者寫入就不管繼續丟下一筆。
Default |
|||
w |
Value |
1 |
指定寫入幾個shard才回應。 數字:指定必須寫入幾個shard才可以回應 • 等於0時,寫入就返回不等server處理。 • 等於1時,等Primary確認就回應。 • 如果j:true,則j:true優先權較高。 • 大於1的數字僅對於replica sets有作用,包含primary寫入對應成功的數字才會返回。 "majority":指定當寫入由sharded clusters決定的”大多數”的數量都成功後回應 <tag set>:寫入具有指定的tag之replica set 才回應 |
j |
Boolean [true,false] |
是否寫入日誌。 日誌:MongoDB有個機制是收到資料不會馬上寫入DB,而是先寫入速度較快的一個硬碟空間,在間隔時間內再寫入DB。 |
|
wtimeout |
Number |
指定要等待多久(milliseconds),當w>1時有效。 如果不指定時間的話,client就會一直等Mongo回應。 超過時間則回應當下失敗的資訊。 |
1.%2 write concern:0(Unacknowledged)
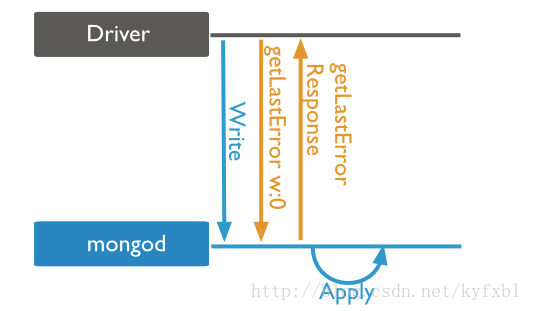
意思就是完全不關注寫入成功與否,只要寫入就返回繼續做client的事情。
write concern:1(acknowledged)
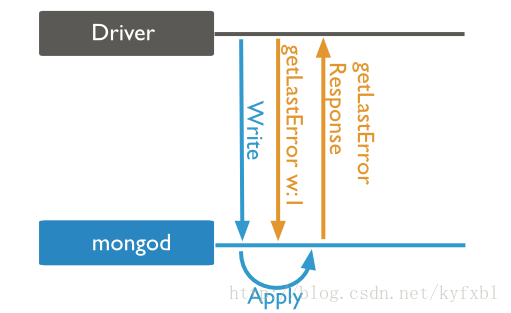
必須等Primary確認寫入後才會回應。
write concern:1 & journal:true(Jounaled)
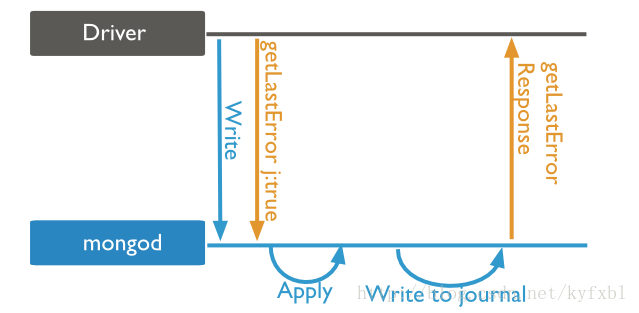
除了Primary寫入完成之後,還必須等journal確認寫入完成,才會返回。
write concern:2(Replica Acknowledged)
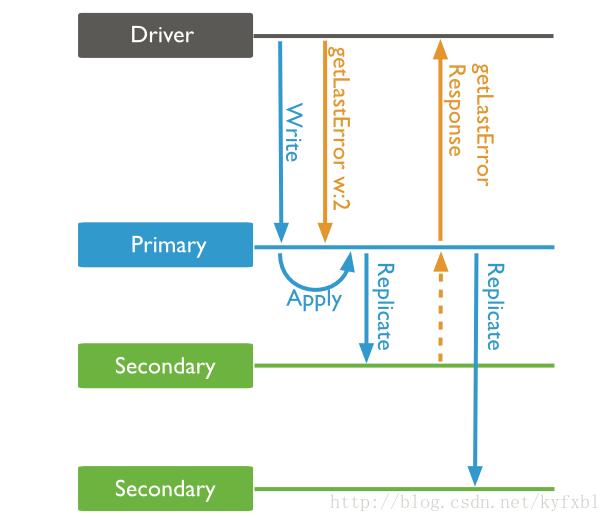
數字2以上的級別必須等待別的shard寫確認寫入之後才會返回。
write concern: majority(Replica Acknowledged)
由整個shard cluster自動決定要寫入幾份shard才回應,通常為1/2的節點數。
11. MongoDB資料的Reference
1.%2 Manual References
寫入資料:
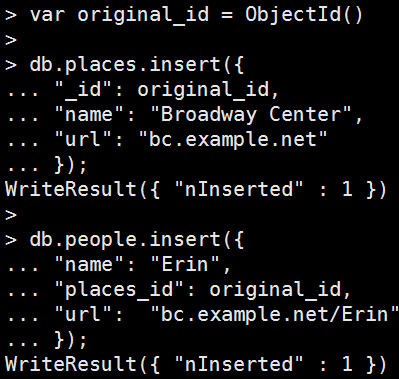
var original_id = ObjectId() db.places.insert({ "_id": original_id, "name": "Broadway Center", "url": "bc.example.net" }); db.people.insert({ "name": "Erin", "places_id": original_id, "url": "bc.example.net/Erin" }); |
|
取用:
Mongo Command |
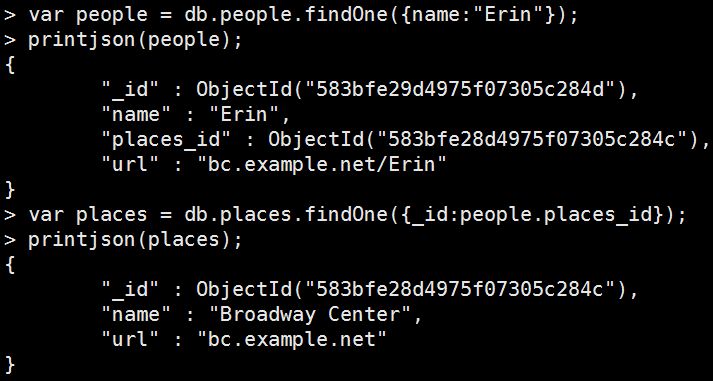
var people = db.people.findOne({name:"Erin"}); printjson(people); var places = db.places.findOne( { _id: people.places_id } ); printjson(places);
|
Java Operate |
MongoCollection<Document> peopleCollection = db.getCollection("people"); Document people = peopleCollection.find(Filters.eq("name", "Erin")).first(); System.out.println(people); MongoCollection<Document> placesCollection = db.getCollection("places"); Document places = placesCollection.find(Filters.eq("_id", people.get("places_id"))).first(); System.out.println(places); |
執行結果:
|

DBRefs
寫入資料:
var buyerId = ObjectId() db.buyer.insertOne({ "_id": buyerId, "name": "Aery", "phone": 1234567 }); db.order.insertMany([ { "_id": 0, "buyer": { "$ref": "buyer", "$id": buyerId }, "goods": "Apple" }, { "_id": 1, "buyer": { "$ref": "buyer", "$id": buyerId }, "goods": "Note Book" } ]); |
|

取用:
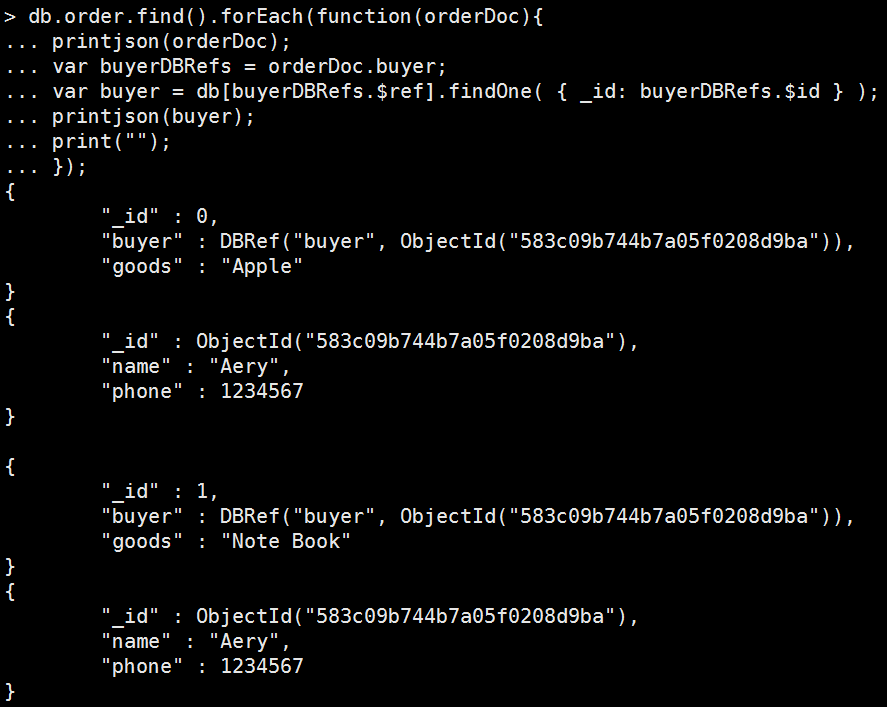
Mongo Command |
db.order.find().forEach(function(orderDoc){ printjson(orderDoc); var buyerDBRefs = orderDoc.buyer; var buyer = db[buyerDBRefs.$ref].findOne( { _id: buyerDBRefs.$id } ); printjson(buyer); print(""); }); 執行結果
|
Java Operate |
MongoCollection<Document> orderCollection = db.getCollection("order"); FindIterable<Document> orderList = orderCollection.find(); Block<Document> doEach = orderDocument -> { DBRef buyerDBRef = orderDocument.get("buyer", DBRef.class); System.out.println(orderDocument);
String collectionName = buyerDBRef.getCollectionName(); Object id = buyerDBRef.getId();
MongoCollection<Document> targetCollection = db.getCollection(collectionName); Document buyerDocument = targetCollection.find(Filters.eq("_id", id)).first(); System.out.println(buyerDocument); System.out.println(); }; orderList.forEach(doEach); |
執行結果:
|

很不幸的,自動查詢看來必須藉由其他框架來達成,例如Spring 的 data mapping 。
12. MongoDB資料的Validation
簡單來說它有點像RDB的欄位限制,例如型態、長度之類的限制,請看以下sample:
db.createCollection( "contacts", { validator: { $or: [ { phone: { $type: "string" } }, { email: { $regex: /@mongodb\.com$/ } }, { status: { $in: [ "Unknown", "Incomplete" ] } } ] } } ); |
很一目瞭然吧,它在描述contacts這個collection裡面的field存放內容的限制。不同於RDB,它甚至可以利用regex限制存放內容,很強大吧!
如果想要建立validation的collection已經存在,則可以使用collMod 來加入validation。
db.runCommand( { collMod: "contacts", validator: { $or: [ { phone: { $exists: true } }, { email: { $exists: true } } ] }, validationLevel: "moderate" } ) |
我們來執行第一份creatCollection的語法並且寫入以下資料測試吧:
db.contacts.insertMany( [ { name: "A" ,phone: "0920271218" ,email: "abc.abc@mongodb.com" ,status: "Unknown" }, { name: "B" ,phone: "0920271218" ,email: "abc.abc@thinkpower.com" ,status: "Unknown" } ], { ordered: false } ); 執行結果:
|
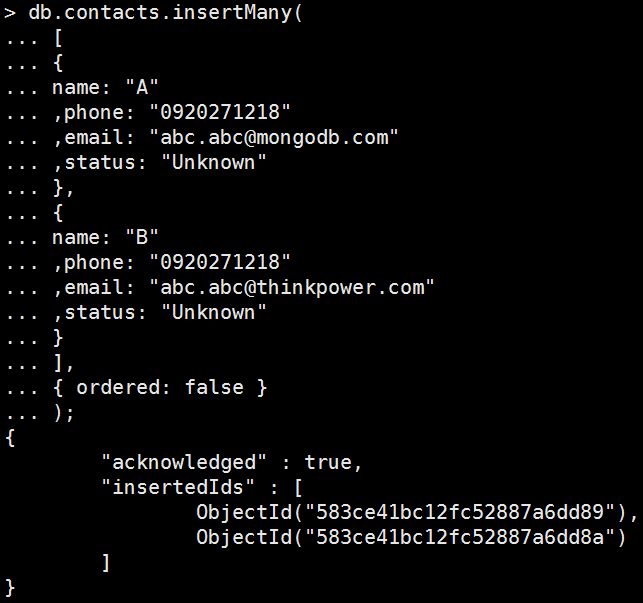
好像哪裡怪怪的?B的email分明不符合validation啊啊啊~怎麼兩筆都寫入了勒?嗯,其實是廢話,因為我在createCollection時的validation使用的是$or,意思就是裡面的條件期符合就好了,所以當然兩筆都可以寫入。
聰明的你應該馬上意識到了,其實這個validator也就是CRUD所使用的查詢條件,只要insert的document能夠被這組查詢出來,它就有資格被寫入,從這個角度思考,其實validator就沒甚麼好說的了,對吧?
我們來試試看將$or改成$and的時候寫入狀況吧。把collection drop掉之後,用改成$and的指令建立collection,然後再寫入一次資料試試看吧:
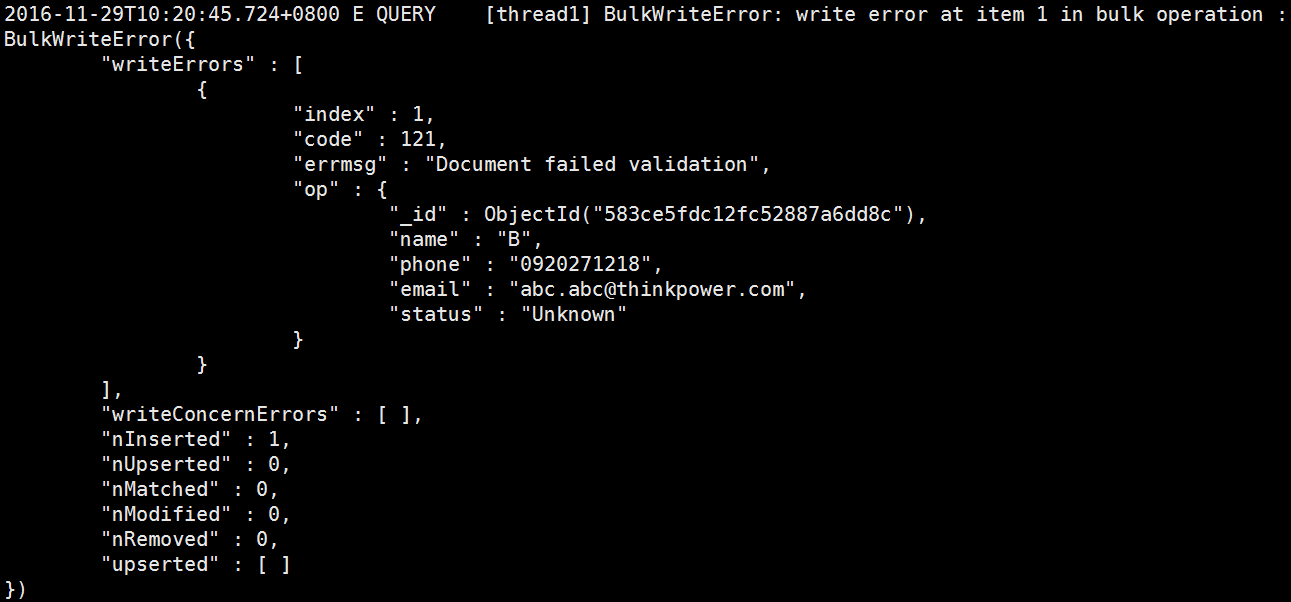
你看,這下子B這傢伙就不能亂入了吧!
13. 參考來源
• Thinking in Documents: Part 1