關聯式資料庫讀寫分離及分表分庫
前言
一般系統對資料庫的讀取(SELECT)及寫入(INSERT、UPDATE、DELETE)都在同一個資料庫,一方面無法滿足互聯網時代海量資料的吞吐率,另一方面也無法滿足業務系統的效能。目前資料庫廠商優化系統效能的速度,遠遠追不上業務發展及資料增長的速度。因此,為了可以因應大數據時代以及提升業務系統效能,必須考慮資料庫集群的方式來提升效能。本篇主要在介紹現行主流的兩種高性能資料庫集群:1)讀寫分離、2)分庫分表。
讀寫分離
讀寫分離主要的基本原理是將讀取和寫入兩種操作分散到不同的資料庫節點上,基本實現如下:
1)資料庫集群包含一台主資料庫伺服器(master)及一台以上的從資料庫伺服器(slave),稱為主從架構(Master-Slave Architecture)
2)master負責讀取和寫入兩種操作,slave只負責讀取操作
3)若master上的資料有異動,會將異動的部分同步到slave
4)業務伺服器(API Server)將寫入分配到master,將讀取分配到slave
讀寫分離的實現邏輯並不複雜,但在實際應用過程中需要考慮資料同步時因各種因素導致同步延遲所帶來的複雜性。
主要導致延遲的因素可能有:
1)大量的資料同步
2)伺服器間連線中斷
3)伺服器分散在不同的環境,網路傳輸速度不同
例如加入會員,使用者完成加入會員後重新登入系統,若採用讀寫分離,使用者登入時可能master和slave資料庫還未完成資料同步,就會發生登入的帳號不存在的窘境,實際上該帳號確實是存在的。類似這種需要即時查詢的業務,則無法使用讀寫分離,需將讀寫操作集中在同一個資料庫伺服器上。
分庫分表
讀寫分離機制分散了資料庫操作的壓力,但並沒有分散資料庫儲存的壓力。像是大型購物平台系統,商品、客戶、訂單等等,資料都會達千萬甚至上億筆,若集中在同一台資料庫伺服器,會導致讀寫的效能下降、資料備援耗費很長的時間、以及各種可能因素導致資料丟失的風險。因此,出現了分表、分庫的分散式儲存做法。
分庫
分庫主要是將業務模組分散到不同的資料庫伺服器,例如會員資料庫、商品資料庫、訂單資料庫等等。原本在同一資料庫裡面的資料,因分庫之後,分散到不同的資料庫,導致無法做join查詢,例如取得訂單的商品內容,需從訂單資料庫的訂單資料取得商品ID,再使用商品ID到商品資料庫查詢商品資訊,一來一往增加了查詢上的操作,相對單一資料庫做join複雜多了。
分表
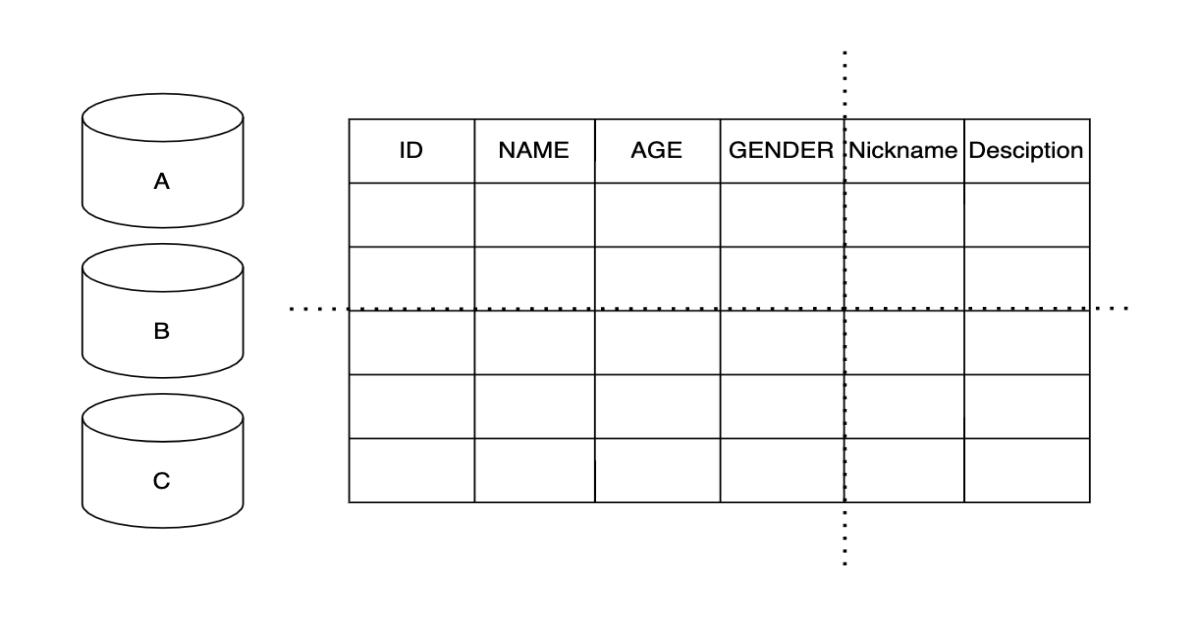
單一資料表拆分有兩種方式:1)垂直拆分、2)水平拆分
垂直拆分是將表格中不常用的欄位切出另外一張表格,例如拆分前有ID、Name、Age、Gender、Nickname、Description六個欄位,其中Nickname、Description為較少使用的欄位,故垂直切分成另外一張表包含ID、Nickname、Description。
水平拆分則適合行數特別多的資料表,例如ID從1到99999在第一張表,ID從100000開始到999999另開一張表來儲存。拆分出來的表都跟主表一致,包含ID、Name、Age、Gender、Nickname、Description六個欄位。水平拆分後,對程式來說都增加了複雜度:
1)如果需要對其他表進行join查詢,需進行多次的join然後再將結果做合併。
2)如果要查詢資料總筆數count,除了可以對多張表做count相加,也可以另外將總筆數紀錄在另外一張記錄表,表格欄位或許只有TableName、TotalRow,每一次進行insert、delete都要去update記錄表的總筆數,若查詢頻率較低的業務,或許可以考慮用排程來更新記錄表總筆數。
3)如果要做order by,只能將主表及拆分表上的資料撈到程式中來進行排序,對程式帶來了不少性能上的壓力。
總結
讀寫分離、分庫分表都是為了提升資料庫性能,前者分散存取資料庫壓力,但沒有分散資料庫存儲的壓力;而後者既可以分散存取壓力,也可以分散儲存壓力。讀寫分離因有同步帶來的時間差,需考慮資料一致性問題,可從業務流程上來判斷操作是否要將讀取及寫入分離到不同的資料庫。分庫分表則需考慮到join、count、order by的操作,程式上會增加不少的操作,分庫也會增加伺服器增加成本的問題。
Reference:李運華(2020/1)。程式設計師從零開始邁向架構師之路。臺北市:深智數位。