DB主鍵(PK)的設計策略
RDB主鍵(PK)的設計策略
PK之必要性:
有些人主張Table不一定要有PK,但是我認應該每一張Table都要有PK,不論是單一或是複合PK,有PK的存在代表著Table的結構完整性,Table的Record能夠被唯一識別,另外PK也表示著其它Table的FK關聯,如果沒有PK那麼我們在操作Table時將會變的非常麻煩。
主鍵的無意義性:
我認為PK不應該具有實際的意義,這可能對於一些朋友來說不太認同,比如「訂單資料表」,會有「訂單編號」的欄位,而這個欄位呢在業務實際中本身就是應該具有唯一性,具有唯一標識記錄的功能,但我是不推薦採用「訂單編號」欄位作為PK,因為具有實際意義的欄位,具有“意義更改”的可能性,比如訂單編號在剛開始的時候我們一切順利,後來客戶說“訂單可以作廢,並重新生成訂單,而且訂單號要保持原訂單號一致”,這樣原來的PK就面臨重覆的危險了。因此雖然人造資料也許可能是刻意不讓它重覆,但經過人為的新、刪、修可能就會不小心重覆,這再次強調人為無法保證不重覆,若設成PK就會造成系統崩潰。因此,我推薦是新設一個欄位專門作為PK,此PK本身在商業邏輯上不必呈現,不具有實際意義。而這種PK設計可降低某些程式的複雜度(因為可不用複合主鍵),且不論您本來的Table設計如何都可以加入無意義的PK。
主鍵的選擇策略:
我們現在在思考一下,應該採用什麽來作表的主鍵比較合理,說明一下,主鍵的設計沒有一個定論,各人有各人的方法,哪怕同一個,在不同的項目中,也會採用不同的主鍵設計原則。
第一:編號作主鍵
此方法就是採用實際業務中的唯一欄位的“編號”作為主鍵設計,這在小型的項目中是推薦這樣做的,因為這可以使項目比較簡單化,但在使用中卻可能帶來一些麻煩,比如要進行“編號修改”時,可能要涉及到很多相關聯的其他表,因為人造資料也可能事後被要求允許重復。無論我們再怎麽先知先覺,都無法預測業務將會修改成什麽?
第二:自動編號主鍵
這種方法也是很多朋友在使用的,就是新建一個ID欄位,自動編號,非常方便也滿足主鍵的原則。
優點是:DB自動編號,速度快,而且是有順序性,聚集型主鍵按順序存放,對於檢索非常有利;數字型的,占用空間小,易排序,在程式中傳遞參數也方便;如果透過非系統增加Record(比如手動錄入,或是用其他工具直接在表裏插入新記錄,或老系統匯入資料)時,非常方便,不用擔心主鍵重復問題。
缺點:其實缺點也就是來自其優點,就是因為自動增長,在手動要插入指定ID的記錄時會顯得麻煩(無法指定編號),尤其是當系統要移植到別的DB時很難保證原系統的ID不發生主鍵衝突(前提是老系統也是數字型的);如果其他系統主鍵不是數字型那就麻煩更大了,會導致修改主鍵數據類型了,這也會導致其他相關表的修改,後果同樣很嚴重;就算其他系統也是數字型的,在導入時,為了區分新老數據,可能想在老數據主鍵前統一加一個“o”(old)來表示這是老數據,那麽自動增長的數字型又面臨一個挑戰。 但是這個問題我們可以在資料順利移植完成後SQL語句來修正,ex:
Old資料表

Import to New資料表+自動編號
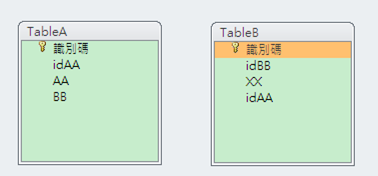
加入原來的關連指令
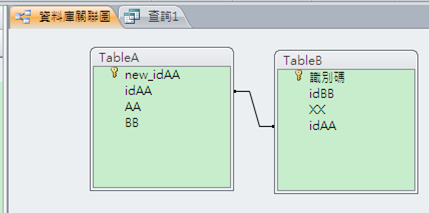
Query SQL命令如下:
SELECT TableA.new_idAA, TableA.idAA, TableA.AA, TableA.BB, TableB.idAA, TableB.XX, TableB.idBB, TableB.識別碼
FROM TableA INNER JOIN TableB ON TableA.idAA = TableB.idAA;
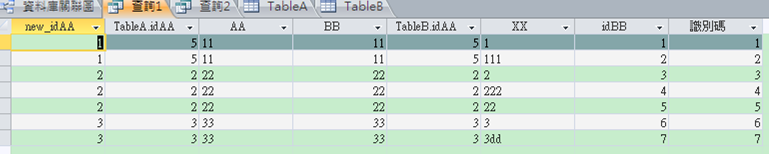
SQL執行如下,注意它仍是用舊的PK。
經過下列 Update SQL命令修正後,已變為使用新加入的 PK。
update 查詢1 set TableB.idAA=TableA.new_idAA; ………(出奇的簡單)
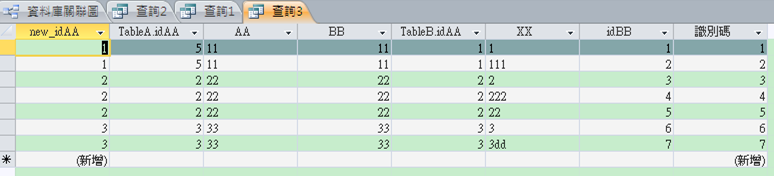
接下來就可以修正TableA and TableB還原成以前的樣子。
-
刪掉 TableA.idAA
-
TableA.new_idAA改為TableA.idAA
-
刪掉TableB.idBB
-
TableB.識別碼改為TableB.idBB
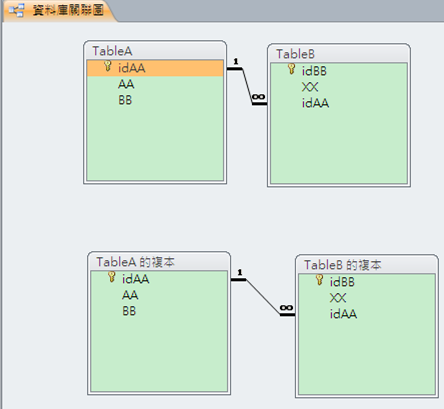
所以說明白點就是只要用上面的紅色字體SQL命令就可以移植資料庫了,而且這個Update SQL 還出奇的簡單。
第三:Max加一
由於自動編號存在那些問題,所以有些朋友就採用自己生成,同樣是數字型的,只是把自動編號去掉了,採用在Insert時,讀取Max值後加一,這種方法可以避免自動編號的問題,但也存在一個效率問題,如果記錄非常大的話,那麽Max()也會影響效率的(sort);更嚴重的是Thread同步問題,如果同時有兩人讀到相同的Max後,加一後插入的ID值會重復,這已經是有經驗教訓的了(高鐵重覆訂位問題)。
第四:自製加一
考慮Max加一的效率後,有朋友採用自制加一,也就是建一個特別的表,欄位為:表名,當前序列值,類似Oracle的Sequence。這樣在往表中插入值時,先從此表中找到相應表的最大值後加一,進行插入,但是仍然無法避免Thread同步問題,我們可以採用Synchronized Thread的方式來避免,在生成此值的時,先Lock,取到值以後,再unLock出來,這樣不會有兩人同時生成了。這比Max加一的速度要快多了。但同樣存在一個問題:在與其他系統合作時(分散式計算),脫離了系統中的Synchronized Thread方法後,無法保證自制表中的最大值與導入後的保持一致。
第五:GUID主鍵
目前個人覺得比較好的主鍵是採用Time+GUID,但值由GUID生成,GUID是可以DB自動生成,也可以程序(Java, C#....)生成,而且鍵值不可能重復(機率太小可略過),可以解決集成系統或移植問題,幾個不同的Table的GUID值導到一起時,也不會發生重復,而且效率很高,因為GUID的不重複性是可跨資料庫與資料表,在.NET裏可以直接使用System.Guid.NewGuid()進行生成,在SQL Server裏也可以使用 NewID()生成。優點是: 與自動增欄位量相比,uniqueidentifier 值可以通過 NewID() 函數提前得知新增加的行 ID,為應用程序的後續處理提供了很大方便, ex:新增Row後, 取得PK, 再異動到其它Table。
便於資料庫移植,其它資料庫中並不一定具有自動增量欄位,而 Guid 列可以作為String轉換到其它資料庫中,同時將應用程序中產生的 GUID 值存入資料庫,它不會對原有數據帶來影響。
便於資料庫初始化,如果應用程序要加載一些初始數據, 自動增量的處理方式就比較麻煩,而 uniqueidentifier 值則無需任何處理,直接用 SQL 加載即可。
便於對某些Object或final或const進行永久標識,ex:類別的 ClassID,Object Instance的實例標識,UDDI 中的聯系人、Service Interface、Model ID定義等。
缺點是:
GUID 值較長,不容易記憶和輸入,而且這個值是隨機、無順序的。
ex:比較難自己手動下SQL取得資料
SELECT * FROM ORDER WHERE ORDERID = 12
比以下這個 SQL 好下多了:
SELECT * FROM ORDER WHERE ORDERGUID = ‘{45F57B42-38A4-46ce-A180-6DE0E7051178}'
GUID 的值有 16 個byte,與其它那些諸如 4byte的整數相比要相對大一些。這意味著如果在資料庫中使用 uniqueidentifier 鍵,可能會帶來兩方面的缺點:存儲空間增大;索引時間較慢。 但是也有學者提出 (組合時間-GUID),稱為COBM GUID,它提供有順序性的GUID值,但重覆的機率會比原生的GUID大些,
我也不是推薦GUID最好(但可考慮增量型組合式GUID ,時間要設定index),其實在不同的情況,我們都可以採用上面的某一種方式,思考了一些利與弊,也方便大家在進行設計時參考。這些也只是我的一點思考而已,而且可能我知識面限制,會有一些誤論在裏面,希望大家有什麽想法歡迎討論。
UUID常用程式寫法:
| Java 如何產生 GUID |
|
| consloe output: |
| f828fa0f-51d8-49c1-83ed-a6943e276274 |
| 當需要使用更少的字元表示GUID時,可能會使用Base64或Ascii85編碼。Base64編碼的GUID有22-24個字元,如: 7QDBkvCA1+B9K/U0vrQx1A 7QDBkvCA1+B9K/U0vrQx1A== Ascii85編碼後是20個字元,如: 5:$Hj:Pf\4RLB9%kU\Lj 但Ascii85字元不利於 http query string 傳送 |
| java使用Base64方法如: http://magiclen.org/java-base64/ String UUID as base64 String(連結) |
INT,UUID,混合型UUID效能測試程式:
Table & 程式碼如下:
for GUID |
for Autoint |
for Autoint+UUID 可以使得select 效率與 autoint 幾乎一樣快 |
| JUnit Test: |
|
效能測試結果:

大量新增row(利用mysql)效能比較圖
在新增完成後執行 select PK 的結果是三種都沒有太大的差別,故這裡就不放上測試圖檔, 但是在新增資料列時, Int 明顯最快, 而UUID因為資料破碎而明顯最慢。
正在維護一個中國同業寫的商用系統,開發者大量用GUID當PK,但資料庫架構一團糟,幾十個table PK欄位都叫做cID,幾乎放棄正規化... 看了真是無語,尤其看到某些簡單的商用規則SP寫下Where cID=‘{45F57B42-38A4-46ce-A180-6DE0E7051178}' 誰能看出它是現在想要抓取分類='A' 嗎? 總共也不過是十多個分類。
我的看法是用GUID當作PK讓經驗不足的開發者做出的系統散發出更多怪味。