淺談 Table Schema設計
淺談 Table Schema設計
前言:
由於做專案,總是躲不掉要面對資料庫這件事。
加上我個人玩過Big Data,有一些對Table Schema的個人看法。
不見得一定能被大家全盤接受,但也是我20年左右的工作經驗(血淚談)。
就分享一下,也希望大家能一起討論。
1、 PK的選擇
我先聲明,不戰流派。因為我是Guid(uuid)流派的忠實擁護者。
為什麼我這麼喜歡用Guid當PK,而不是選用自然型PK或是複合型PK?
我的考量如下:
n 唯一性
² Guid的唯一性是很高的,能撞出相同Guid的機率,從黑暗執行緒大大的文章中可以得知:依據維基百科,預估的機率是 2.71 * 10^18 分之一,若每秒產生 10 億個 UUID 連續 85 年,將有 50% 的機率至少發生一次重複。如果你很想目睹 GUID 強碰,必須產生 103 百萬兆個 UUID,才會有 10 億分之一的重複機率。
n 程式撰寫方便性
² 畢竟目前我使用的是c# 語言,又走物件導向程式設計 + ORM,我需要PK是能由程式自行掌控並產生的,而無需再透過資料庫來取得。
而Guid,在C#裡,可以自行產生一個Guid,語法為:Guid.NewGuid()。
n 資訊安全
² 因為用自然型PK或是複合型PK,有的值還是很好被人一眼就記住。站在資訊安全的立場,至少Guid不是那麼容易被人一眼就記住的。至少我是沒法一眼就把Guid背起來的。神人級的就不用提了…
n 連續性
² 這個,就是在指用流水編號當pk的缺點。因為流水編號產生的PK,在資料被刪除時,資料面上來看,就是斷了連續性。這在某些時候,要分析資料,是會造成困擾的。
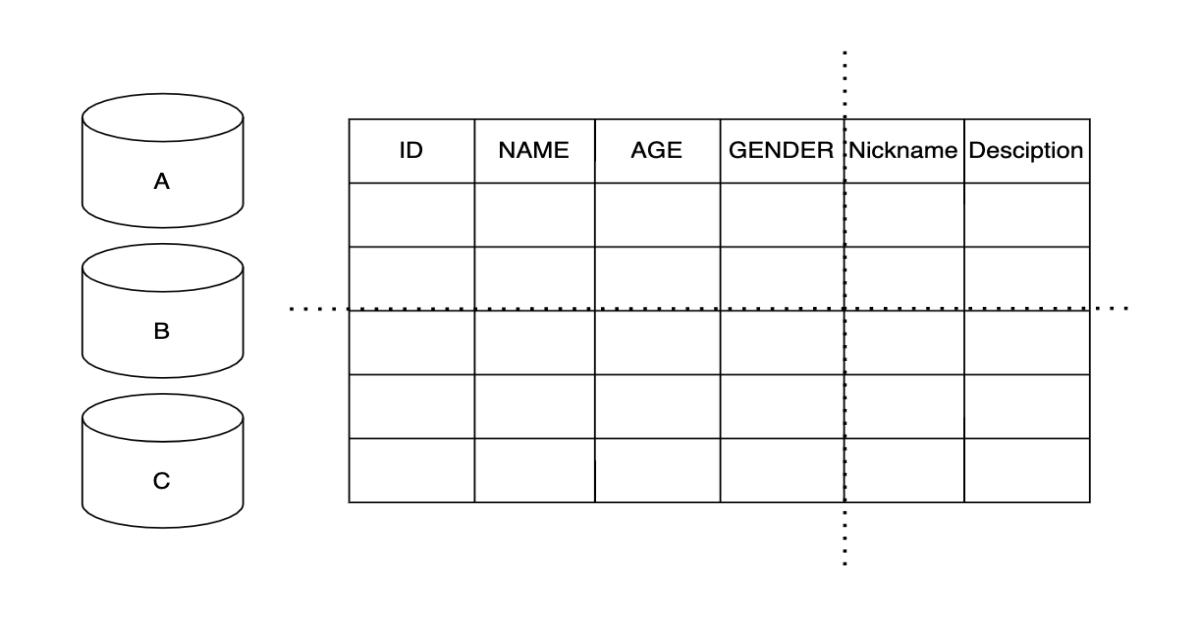
2、 FK是否需要被建立?
我個人的看法是,只要有需要,FK就該做,甚至是正規化該做的,就該做。最多就是在資料分析或做報表時,再另外開一個非正規化的統合Table。
用我前同事的說法:「用空間換取時間」。
翻譯一下:「用硬碟的空間來換取執行效能(時間),畢竟硬碟現在是越來越便宜。又不是386時代,一顆高容量硬碟貴鬆鬆。」
3、 垃圾資料(Garbage Information)
我是非常不喜歡我的資料庫裡有所謂的垃圾資料。
所以,在初始設計時,一定會把關聯性整理好,該開的關聯Table就開一開,讓資料的正確性拉高,讓資料庫盡量看來是乾淨的。
缺點就是會造成程式開發上,會有一定的麻煩程度。
但為了資料乾淨,我還是會情願在寫程式時,多花點時間的。
4、 欄位命名
基本上,我是沿用了c#的命名習慣,盡量用大駝峰式的命名規則。
不愛看到底線之類的。
5、 欄位型態
這邊,盡量能精準就精準。
能開char,就不用開到varchar。
但數字部份,反而是建議一開始就談好。
因為數字很敏感,尤其是在做金融業的案子。
我個人習慣,當這個案子是金融業相關的案子,我都會先問,是否要先固定最大的數字就開到decimal(24,2)。其他的,再看是要整數(int),還是double?
6、 下拉式選單統整表
這個,就是看專案而定了。
但我個人是不喜歡的。我的看法是:下拉式選單本來就應該是固定的。應該用enum去建立好就好,效能也會是最快的。
有可能要變動的,再開table去存放資料既可。
但畢竟做專案,總是會遇到要有彈性、要好維護等理由…
所以這點,我也沒那麼堅持了。(年紀大了,要養家活口,要面對現實)
7、 圖片、影像、上傳等檔案的儲存
基本上,我是反對把這些東西存放在RDBMS資料庫中的。
它們應該是屬於檔案伺服器或Non Sql資料庫該管理的東西。
RDBMS最多就是記其存取路徑等相關資訊既可。
但在某些時候,某些客戶為了法律及資訊安全,再加上成本的關係,這些東西還是不得不存放在RDBMS中。
(前提:需事先跟客戶聲明,這些是會影響到資料庫存取效能的,別答應了客戶把東西放在資料庫後,客戶又要求要高效能。那真的會是欲哭無淚。)
8、 地址相關欄位
這個,看客戶屬性、專案屬性而定。
因為有遇過要很嚴謹的地址欄位設計(物流業、租貸業)。
也遇過不需要到那麼細的地址欄位設計(中小企業)。
9、 報表相關table設計
這個部份,最常遇到的就是日報、週報、月報、季報、年報這五大報表的設計了。
這邊,一定要在專案開發初期,就先和客戶確認好,是否有需要這五大報表。
因為如果需要的話,整個資料庫設計,要從日報為基礎,再去做7天的統計做週報,28~31天的統計資料做月報。
季報的話,偷懶點就用3個月的月報做基礎既可。
年報的話,偷懶點就用12個月的月報做基礎既可。
另外,報表的部份,滿常是統計資料的。
所以一定要考慮相關維度及索引是否有建好建滿。
10、 重覆性
玩資料,總是躲不掉有可能產生重覆資料的問題。
這個就是考驗功力的時候。
不過,就算是我,也常常在這塊撞到牆。
因為總是沒法預期使用者是否會照我們所規劃的去輸入資料。
也曾經在資料分析,為了處理重覆資料花了不少時間及成本。
更不用說在對帳或出報表時,為了找那一二元的多或少。
11、 效能
這個,我只能說,盡人事聽天命。
因為最佳的查詢sql,不是人類能直接寫出來的。
是要經過軟體優化的。
我看過優化後的sql,那真的不是我平常會寫出來的sql。
但效能真的差很多。
所以,要是有人說他寫的sql一定效能是最好的…
我現在只會默默的os:不會比優化軟體翻譯出來的好。
(年輕時還真的曾經當面指正過講師,讓對方下不了台…)
但在業界這麼多年,我也只曾在某一間公司使用過軟體優化sql,離開後,就沒再看到有公司或case是這樣玩了。
後記:
以上純是個人看法及分享。
盡量不要寫的那麼硬,偏一般上課用的說法。
這樣才符合標題中的淺談。XD
大家有什麼想法或看法,非常歡迎留言討論或指正。