Cassandra基本觀念與使用簡介
1.Cassandra介紹
Cassandra為Facebook原為了應對電子郵件的查詢效能所設計出來,結合Google Big Table與Amazon DynamoDB的資料模型與分散式架構所設計,於2008年開放原始程式,因其良好的延伸性與效能被各大網站所使用,成為了目前最流行的分散式資料儲存架構的方案之一。在db-engines 2020的調查中目前是使用普及率為第十,在各個原有relational DB的佔有率下還有此表現實在不易。
Cassandra被歸屬在wide column stores分類中,查詢相關文件後得知,wide column stores意指可被幾乎無限延伸欄位(Column)的資料架構設計,如果需要具備無限可伸縮性的應用,能夠不受限制的擴展比更豐富的功能更加重要,那麼 wide column stores 這類型的資料庫是目前的首選(另外一個則是HBase)。
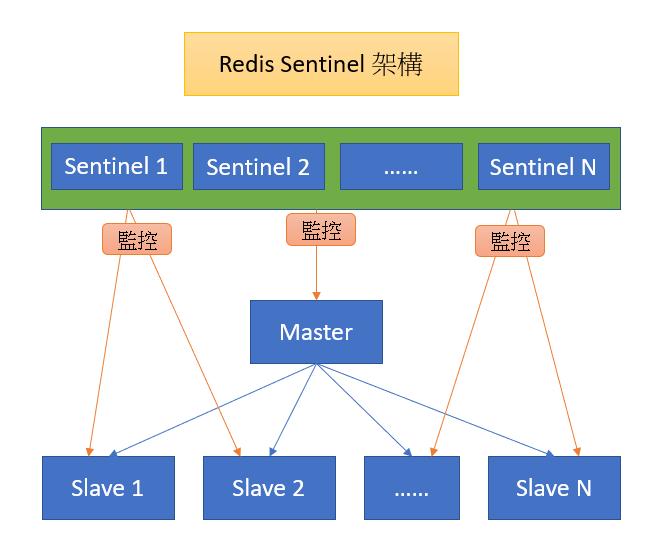
Cassandra採用的是分散式架構,由多台的Node Server作為資料互相複製的方式,確保單一Node出現問題導致資料遺失時仍可確保其他Node還可正常運作存取,跟各個分散式系統一樣,會有Data Center/Cluster/mem-table/SStable控制各Node間的資料存取與查詢效能及資料的一致性,詳細架構介紹請參考相關網頁說明。
The Cassandra Query Language (CQL):CQL為Cassandra提供一個定義接近SQL的語法,採用table/row/column等相同定義的名稱去描述Cassandra的Data Model,讓使用者可以更快速的學習使用它。
2.安裝Cassandra與其他應用程式
2.1 安裝Cassandra
首先到Apache Cassandra下載bin.tar.gz檔案,解壓縮後執行至bin資料夾底下執行Cassandra檔即可。
2.2 安裝Python
實作部分會使用Jupyter Notebook來當作Cassandra的指令操作介面,而本次實作是在該Web base IDE上使用Python語法,故得先安裝Python,相關安裝方式請參考Python官網或其他網頁介紹。
2.3 安裝Jupyter Notebook
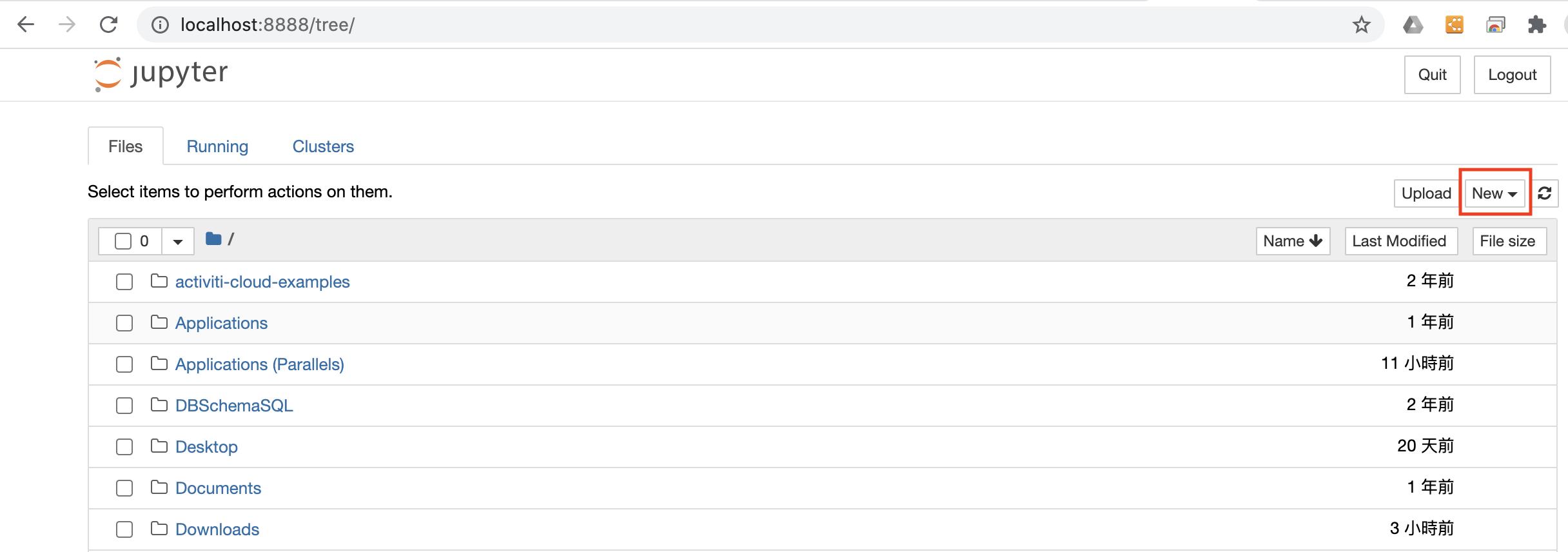
Jupyter Notebook是採用Web base的筆記式程式與指令編輯界面,可以先寫好相關指令後再依序執行,或是針對某個指令重新執行,相比Command Mode的執行方式方便許多,執行的檔案也可以另外儲存作為保留,安裝方式請參考其他網頁介紹,筆者是採用pip的方式安裝。安裝完後在Command Mode上直接以指令方式執行jupyter notebook後,會直接打開電腦預設瀏覽器並顯示編輯畫面,參考畫面如下:
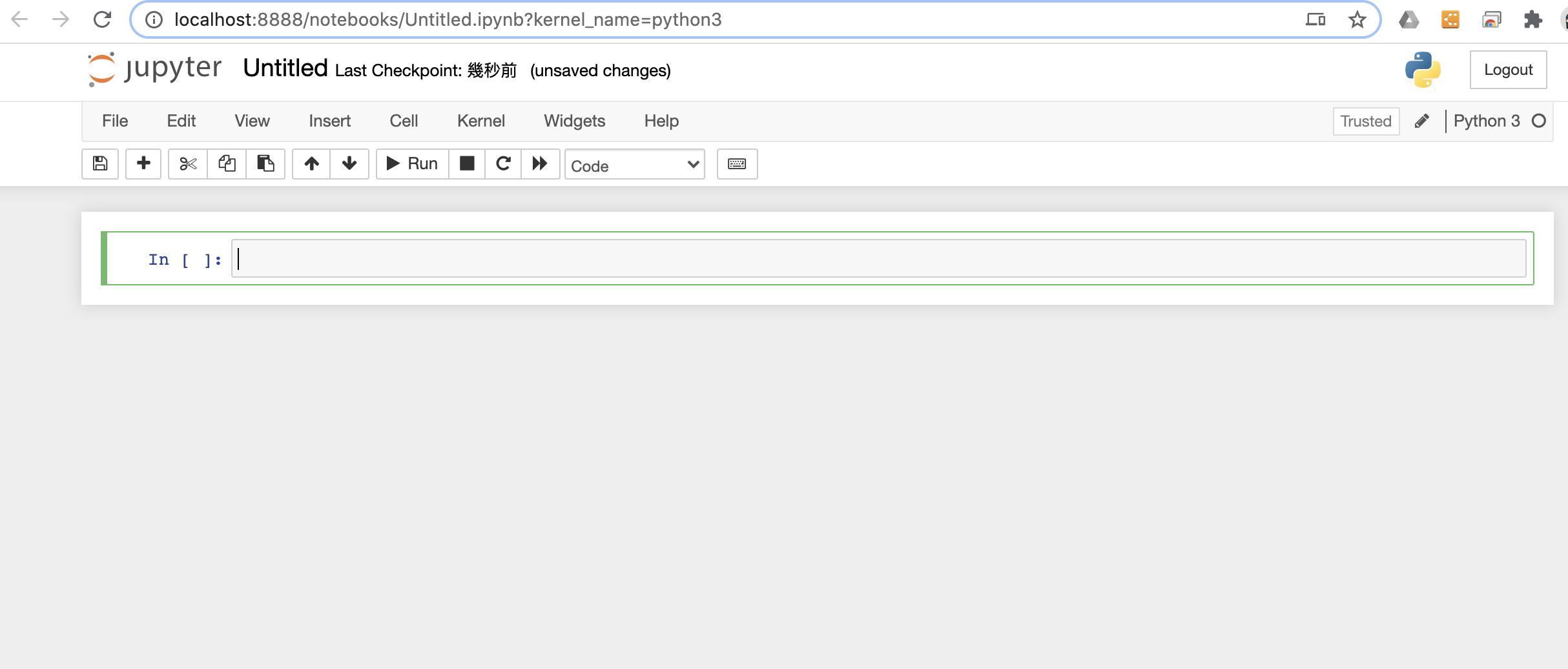
按下右上角的New button之後,即可打開新的編譯畫面,參考畫面如下
2.4 安裝Cassandra driver
採用Python client driver作為Cassandra指令執行,得先安裝Python提供的指令庫(Library),相關說明請參考官方網頁 ,一樣在Command Mode執行以下指令
pip install cassandra-driver
安裝後完畢即可在Jupyter Notebook開始操作Cassandra DB。
3.在Cassandra建立Table與基本CQL指令
3.1 Import Apache Cassandra python package

首先要先將python提供的library import進來。
3.2 建立資料庫連結

Import Cassandra的cluster模組,並建立Cassandra DB服務的連結。
3.3 查詢還未建立的Table並查看錯誤訊息
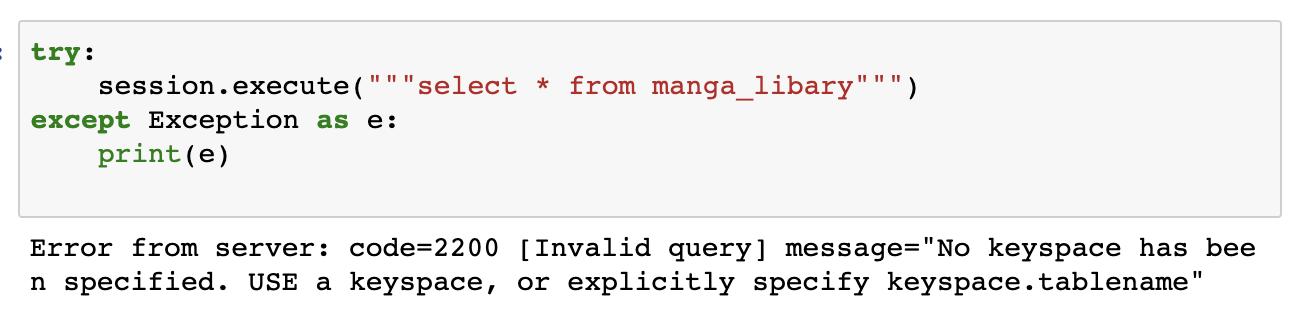
這裡先試著執行一個還未存在的Table查詢,可以看到回傳的錯誤訊息指出沒有keyspace被指定,故得知須先建立keyspace才可以做後續的使用。
3.4 建立Keyspace

Keyspace在Cassandra裏意指建立一可被使用的DB,內含DB的各種用戶設定、資料與索引等等。Replication則是對此數據庫(空間)做進一步的分散式架構與Node指定,相關內容請查閱官網資料。
3.5 連結建立的Keyspace

3.6 建立資料表

建立一個簡易的資料表manga_library作為之後測試的使用。這裏以兩個欄位建立主鍵,要說明的是,在Cassandra建立Primary key如果是Composite的話, 第一個是partition key, 第二個是cluster columns,是拿來排序用的。
partition key:意指該筆資料被雜湊(hash)計算後存放位置的依據,相同的partition key值會被存放在相同partiton的位置,也是日後查詢條件的依據。partition key也可以是複合的key,宣告時再以小括弧區分,例如PRIMARY KEY((a, b) c)寫法。
cluster columns:宣告主鍵時排在partition key之後的各個欄位都是cluster columns,是用來排序每筆存放資料的順序依據。相關詳細內容說明也請查閱官網。
3.7 Insert測試資料

3.8 查詢測試資料
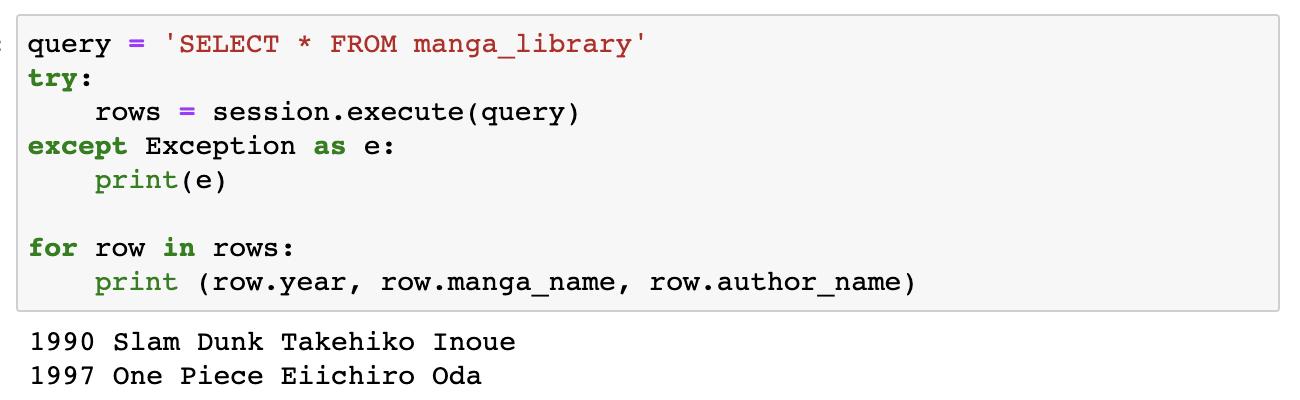
這裡可以看到我們之前Insert兩筆資料的內容,可以用for迴圈將rows物件的資料print出來確認。
3.9 增加查詢條件測試

使用partiton key欄位作為限制條件時可以查詢出資料結果。
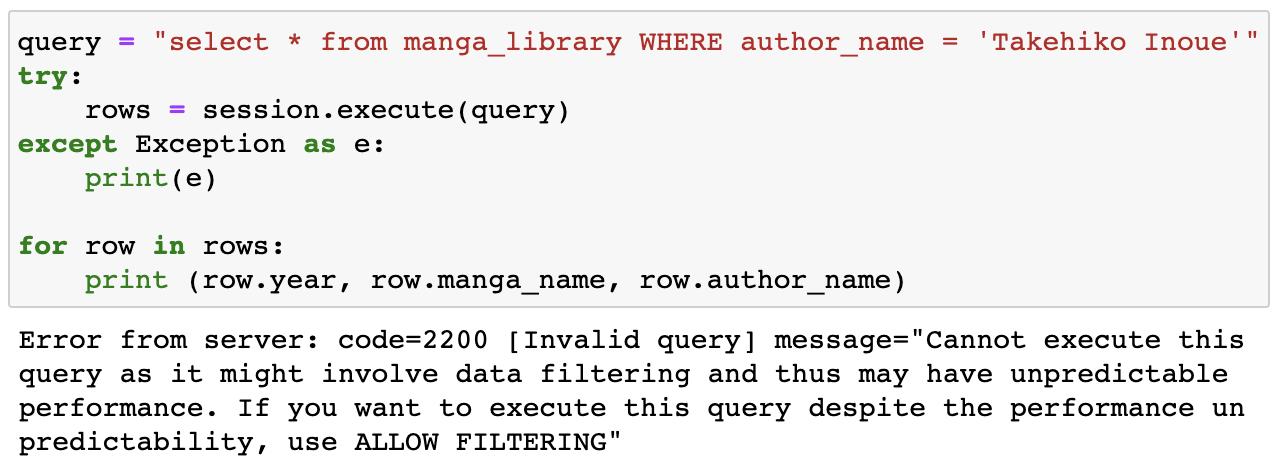
要注意這裡的是當使用限制條件Where時,一定要使用到partition key的欄位作為限制條件去查詢,如果是拿其他任何欄位,包含Cluster Columns時,系統會回傳錯誤訊息,無效的查詢。
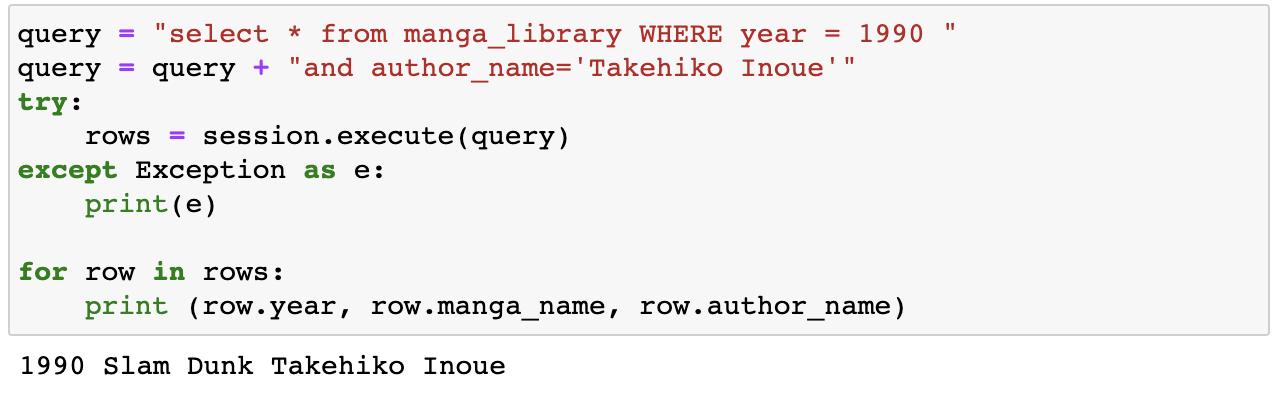
只有將partition key作為主要查詢條件,後續再加上其他查詢欄位才可以被查詢出結果。
3.10 刪除測試資料表

3.11 關掉Session與Cluster

4.結碖
本文為筆者初步學習使用Cassandra與CQL的心得,對於其不同於Relational DB的設計與主鍵的設定與使用方式也大感意外與興趣,本篇在安裝與使用工具設定上花了一些篇幅,希望能縮短讀者的學習曲線。寄望後續能夠繼續完成CQL語法的使用說明與Cassandra DB運用實作,並結合AWS環境的使用,作為後續文章的寫作。
5.參考
5.1 維基百科介紹:https://zh.wikipedia.org/wiki/Cassandra
5.2 Apach Cassandra官網:https://cassandra.apache.org/
5.3 DB-Engines:https://db-engines.com/en/ranking
5.4 Tutorialspoint:https://www.tutorialspoint.com/cassandra/
5.5 Jupyter:https://jupyter.org/