Fraud Detection with Neo4j - PaySim

圖數據逐漸成為市場主流,在這一篇文章中,不會討論圖形化資料庫基本概念,而會以圖數據的應用為主。
本篇將以PaySim做為Data Set,主要分為兩個部分。第一個部分為使用Neo4j 來對第一方金融詐騙進行偵測,第二個部分結合Graph Algorithms 與 Machine Learning做金融詐欺預測。
前言
為什麼當前的反詐欺策略未能識別所以詐欺事件?
雖然現在的資料科學家已經開發的嚴格的機器學習和分析模型來偵測詐欺。但當前的反詐欺模型並未能識別所有詐欺事件。主要的原因是大多數的模型忽略了一些至關重要的東西:網路結構。
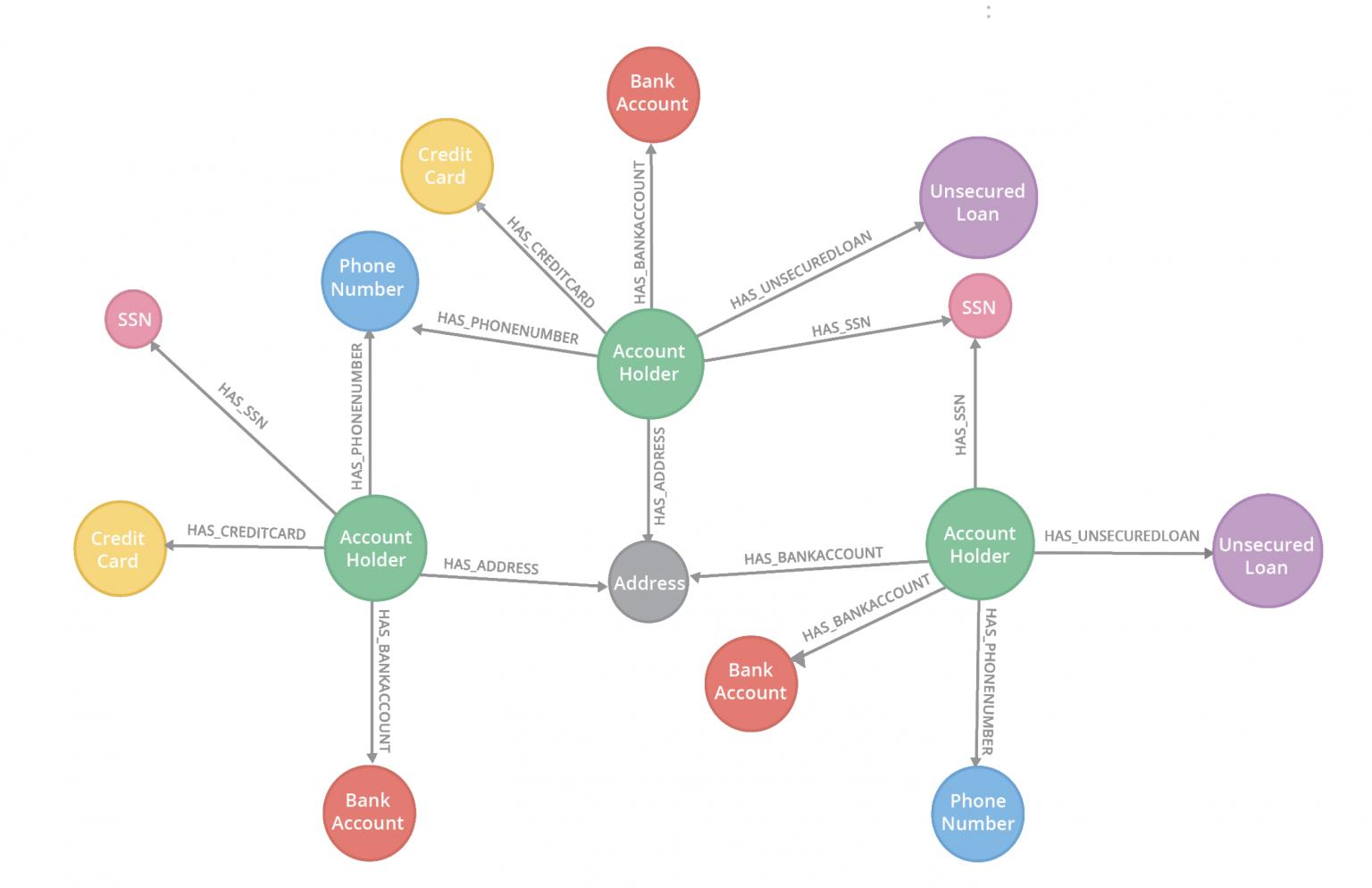
網路分析捕捉數據元素之間的內在聯繫。我們習慣把社交網路數據看作一個圖,但事實上,任何類型的數據都可以用這種方式表示。例如,可以將帳戶持有人及其訊息可視化為一個圖。當我們在分析帳戶持有人訊息的網路結構時,可能會發現多個帳戶持有人的電話號碼或是其他個人身份資訊(Personally identifiable information, PII)相同。共享相同的PII可能表明共用身份詐欺。通常這些類型的詐欺的痕跡很難被發現,除了使用圖算法之外,沒有一種有效的方法來檢查成千上萬或是數百萬帳戶持有人的龐大網路結構。
表格類型數據模型,以行和列所組成,但其模型並不是為了捕捉數據中固有的複雜關係和網路結構所設計的。如果我們將數據建構為一個圖,會方便我們揭示他的結構並且對其進行分析和預測。通過使用圖形資料庫,我們可以將這些網路結構持久化存儲,以便以後進行分析。
用於詐欺偵測的圖數據科學
我們可以藉由圖分析和圖特徵工程來提昇預測準確度。 一旦數據在圖數據庫中連接起來構成了網絡圖結構,就有可能通過圖結構衍生出許多有用的圖特徵,例如節點的出度,入度,潛在三角形群體的數量或共同鄰居的計數,例如社區檢測算法突出顯示數據所在的簇結構(類似聚類),以便可以調查可能的欺詐群體,並深入挖掘不尋常的模式。
使用圖數據科學,可以在不改變當前機器學習系統的情況下檢測到已經擁有的數據中的更多欺詐行為。 簡單來所就是在特徵工程的過程中引入更多的基於圖的圖特徵;


事前需求
Neo4j 4.0+
Graph Data Science Library (Neo4j GDS 1.5+)
APOC Library (Neo4j APOC 3.5+)
資料集
PaySim
由Lopez-Rojas, Elmire, and Axelsson發表,使用基於代理模型(agent-based model)和一些匿名的,來自真實行動支付網路營運商的交易數據,所創建的金融數據集。
PaySim數據集涉及銀行(Banks)和參與其中的商家(Merchants)。商家(Merchants)可以透過網路(network)進行行動支付,也可以向網路(network)投入金錢(像是儲值)。
可以簡單把他想像成Apple Pay,但你可以透過參與的商家進行存款。
Agent Types(代理種類):
以下是三個主要代理(Agents)在圖網路中。
Clients(客戶)
客戶(Clients)是最終使用者在行動支付網路中,為真人控制的獨特帳戶。
* 一些客戶是詐欺犯(Fraudsters),操縱網路(Network)和其他客戶(Clients)為了自己的利益。
* 一些客戶扮演騾子(Mules)的角色,負責轉移資金並最終離開網路(Network)的方式
* 大多數的客戶都是表現正常的正常人
Merchants(商家)
商家代表供應商(vendors)或是企業(Businesses)與客戶(Client)在網路中互動。
* 商家(Merchants)扮演網路的關口(Gateway),允許資金進出網路
* 商家(Merchants)像傳統的供應商(Vendors)一樣在網路中提供商品或服務換取金錢
Banks(銀行)
銀行扮演著借記帳(Debit transactions)的角色。
Transactions(交易):
交易是客戶(Clients)與其他代理(Agents)進行互動的唯一途徑。事實上,客戶(Clients)是執行交易(Transactions)的唯一代理(Agent)。
以下為五種交易可能類型:
* CashIn: 客戶(Client)透過商家(Merchant)將資金轉移到網路中
* CashOut: 客戶透過商家將資金轉移出網路
* Debit: 客戶將資金轉入銀行
* Transfer: 客戶向另一位客戶匯款
* Payment: 客戶(Client)用金錢從商家(Merchant)換取某物
我們如何藉由圖數據庫來識別潛在的第一方金融詐騙犯呢?
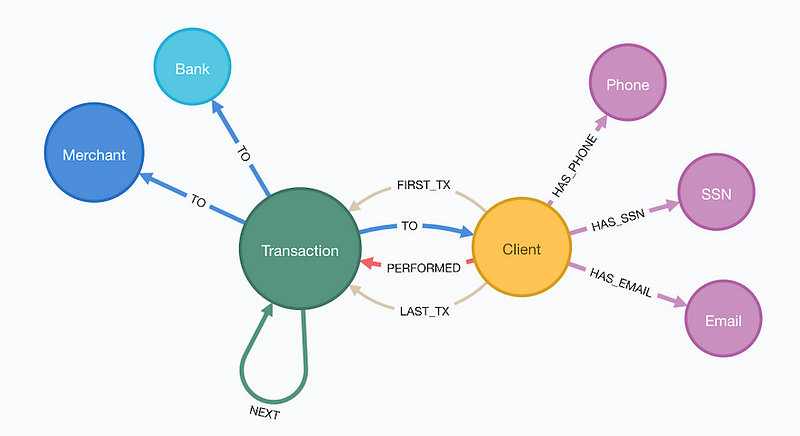
Explore Data
首先第一步,探索我們的PaySim資料集。
Stats:
CALL apoc.meta.stats();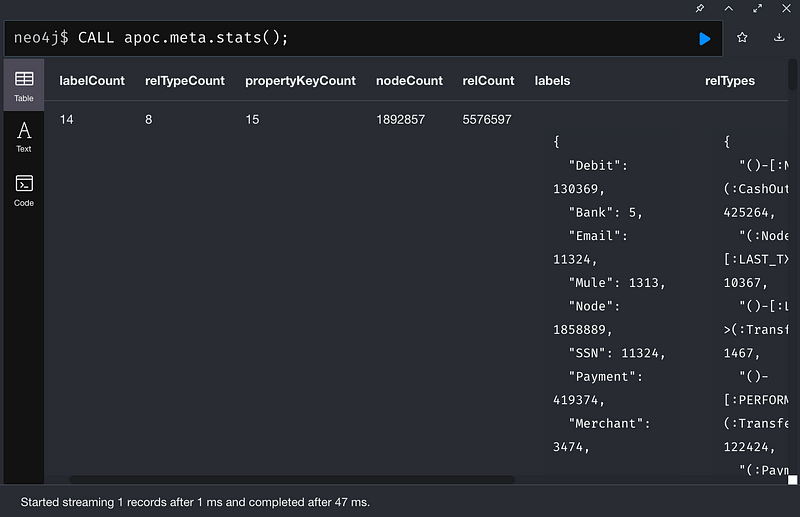
列出所有節點(Node)及對應頻率(Relative Frequency):

從上圖看得出我們大部分(62%)的交易活動是透過CashIn和CashOut 資金流入或流出網路。
Transactions本身有什麼有趣的地方嗎?
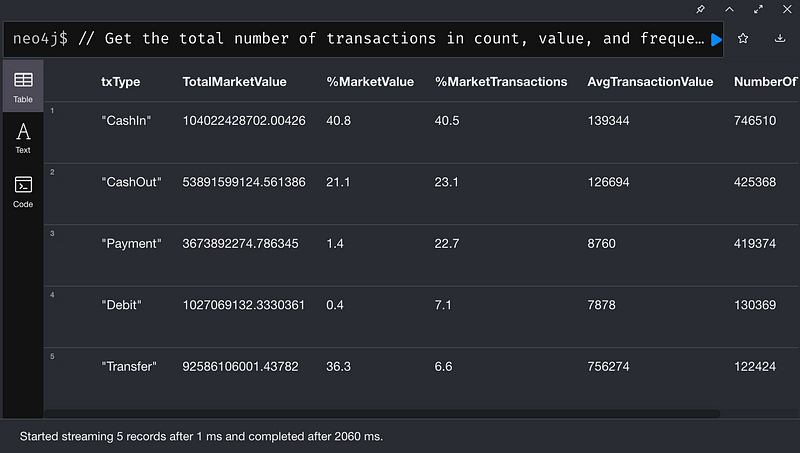
從上圖可以看出,CashIn 在交易數量和平均交易規模佔主導地位。但有趣的是,Transfer佔整個交易總金額1/3以上,儘管Transfer總交易量只有6%左右。實際上,平均Transfer所涉及的資金是 CashIn的6.25倍左右!
第一方詐騙(First Party Fraud)
第一方詐騙主要是個人(或群體)在申請金融產品或服務時謊報身份或提供虛假訊息。
根據 McKinsey, 增長最快的第一方詐欺類行為虛假身份詐欺( synthetic identity fraud). 在虛假合成身份詐騙( synthetic identity fraud)中,詐騙者通常結合虛假和真實的訊息,在新的合成身份下建立信用紀錄。這類欺詐行為給金融機構造成重大損失,據估計,80%的信用卡詐騙損失都是由於偽造合成身份詐騙( synthetic identity fraud)造成的
在PaySim裡,這些詐騙者會生成諸如電子郵件、SSNs、電話號碼等個人身份資訊(Personally identifiable information, PII),並在網路中混合成不同組合。在未來某個時候,這些詐騙者通過一個中間人(騾子, Mule) CashOut 資金在這個行動網路中。
我們將會執行以下的步驟,來揪出這些詐騙帳號:
1. 識別共享個人身份資訊(Personally identifiable information, PII)的客戶(Clients)
2. 使用社區檢測算法(Community Detection Algorithms)識別共享PII的客戶群集
3. 使用成對相似算法(Pairwise Similarity Algorithms)在基於共享PII的客戶群集中找到相似的客戶
4. 使用中心性算法(Centrality Algorithms)為共享PII的客戶群集計算詐騙評分(Fraud Score)
5. 使用上述的分數來標記潛在的詐騙犯
1. 識別共享個人身份資訊(Personally identifiable information, PII)的客戶
a. 找出共享PII 的一對客戶:
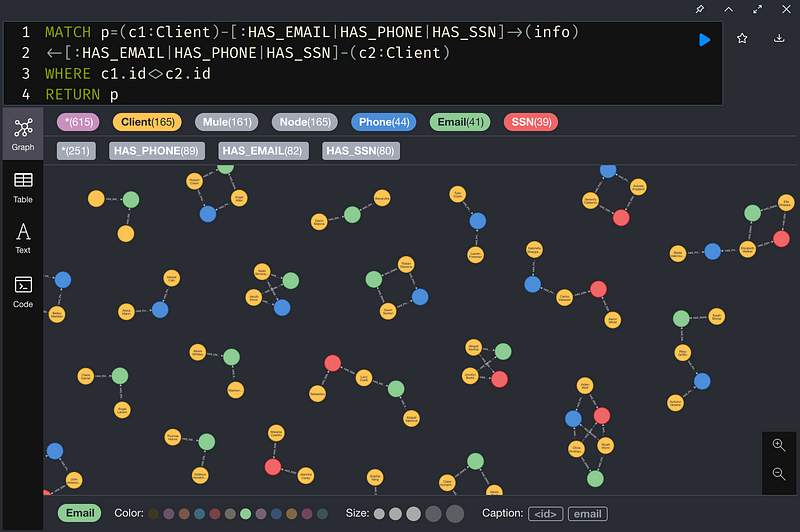
b. 創建一個新關係(Relationship)連結共享PII的客戶,並將共享PII的數量當作該關係的屬性添加
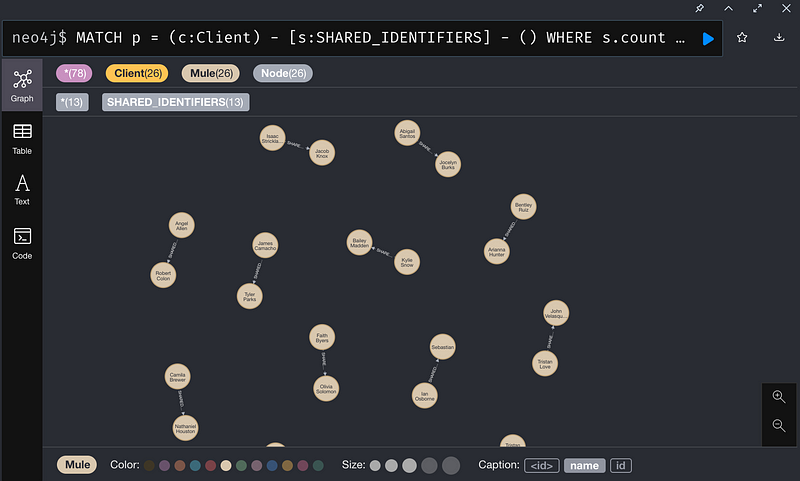
2. 識別共享PII的顧客群集(Clusters)
在這邊,運行GDS Library的社區檢測算法(Community Detection algorithms)來識別共享PII的客戶群集。
我們使用弱連通連結(Weak Connected Components)來尋找一個群集連接的節點,其中在同一個群集中的所有節點構成一個連接的組件。
弱連通連結(Weak Connected Components)對圖進行分析,識別”圖組件(Graph Components)”。組件是一組節點與關係,在這些節點和關係中,可以透過遍歷從任何其他節點到達每個成員(節點)。之所以被稱為弱,因為並沒有考慮到關係的方向性。
弱連通連結(Weak Connected Components)通常用於分析的早期,以理解圖的結構。
更多訊息: Weakly Connected Components — Neo4j Graph Data Science
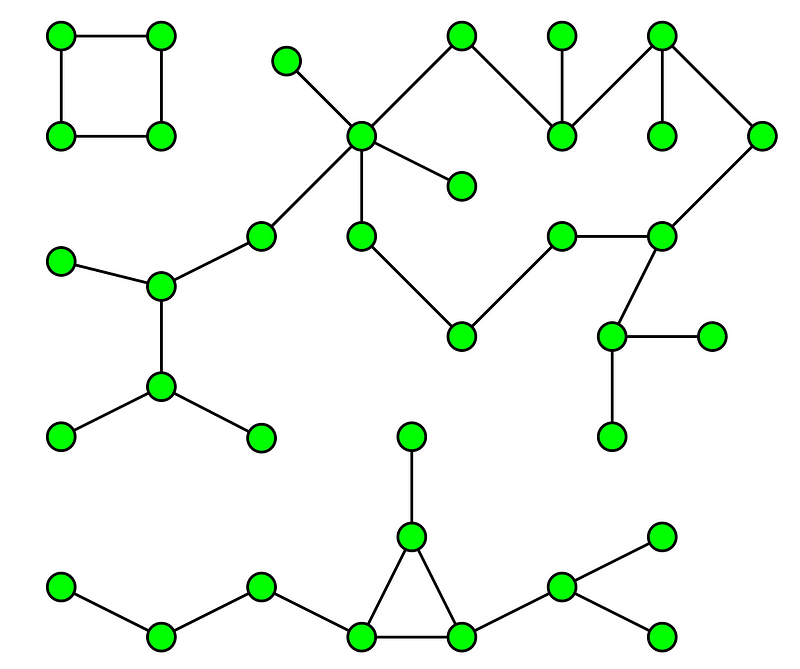
3. 在顧客群集中找出類似的客戶
透過運行GDS 成對相似算法(Pairwise Similarity Algorithms),在顧客集群中找出相似的客戶。
節點相似度(Node similarity),根據與其他節點的關係找到相似的節點。節點相似度使用Jaccard距離,通過觀察網路中兩點節點共有的相關節點除已與兩個節點相關的所有節點的和,來計算一對節點的相似性分數。
更多訊息參考:Node Similarity — Neo4j Graph Data Science
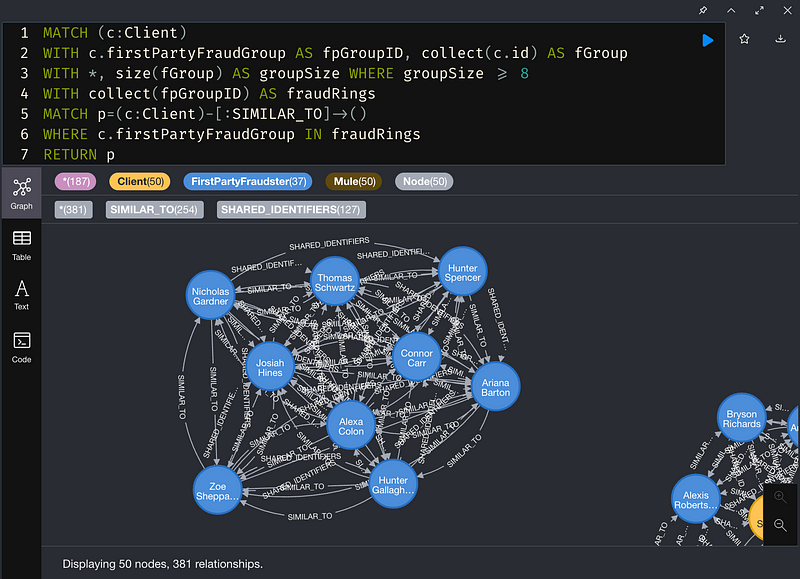
4. 計算詐騙分數 (Fraud Score)
使用一種中心性算法(Centrality Algorithms)-Degree Centrality,將集群中給定節點的傳入和傳出關係上的Jaccard Score相加,並將其分配為向硬的Fraud Score。 這裡假設Fraud Score越高,發生詐欺的可能性就越大
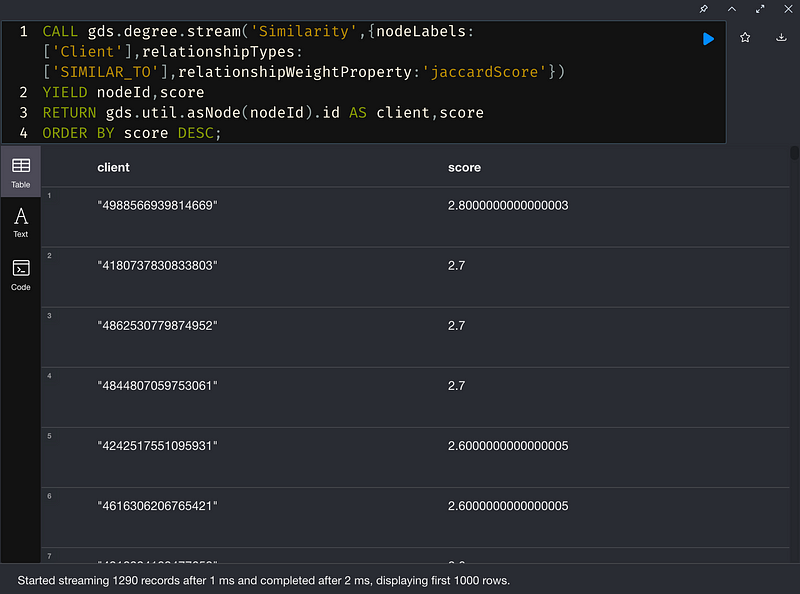
5. 標記潛在詐騙犯
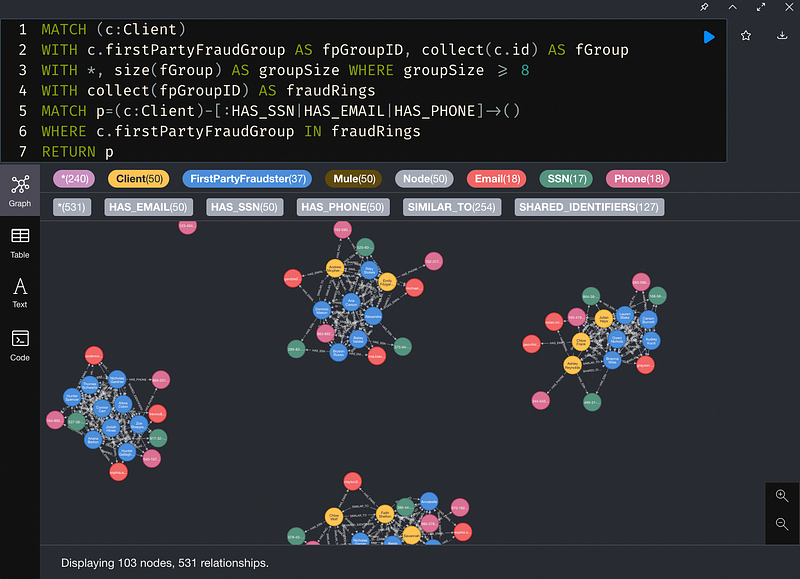
探索第一方詐欺評分大於某個閥域值的客戶。在本文裡,使用第80個百分位數作為閥域值。

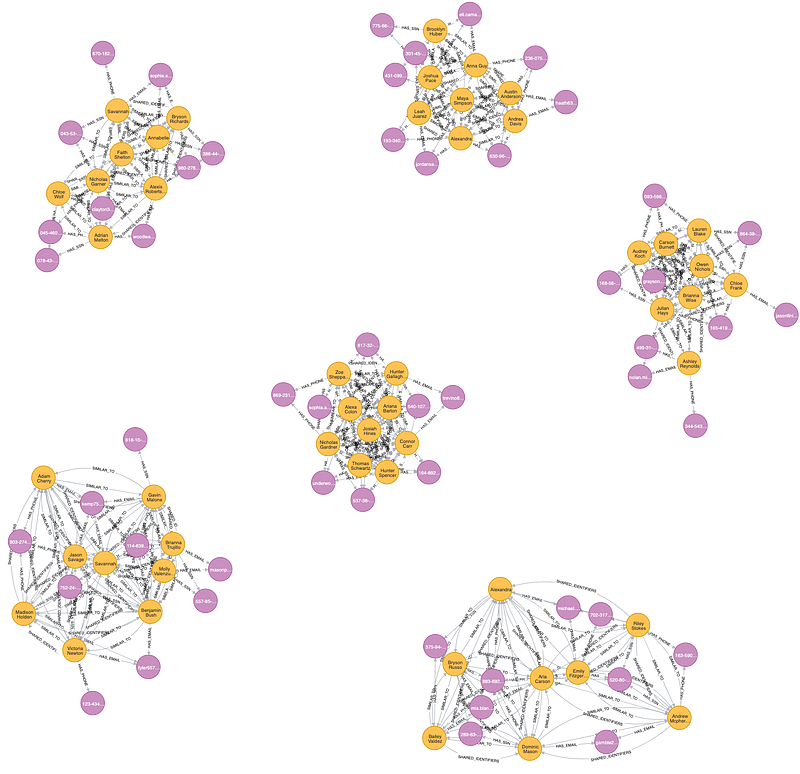
從上圖可以看到六個群集包含少量的客戶(黃色的節點),似乎共享SSN、Email、電話號碼等PII(紫色的節點)
找出 2nd-level Fraudster
現在我們已經確定了一些可疑群集的客戶,接著查看與這些可疑客戶交易的其他客戶。
找出與這些詐騙群集有聯繫的人
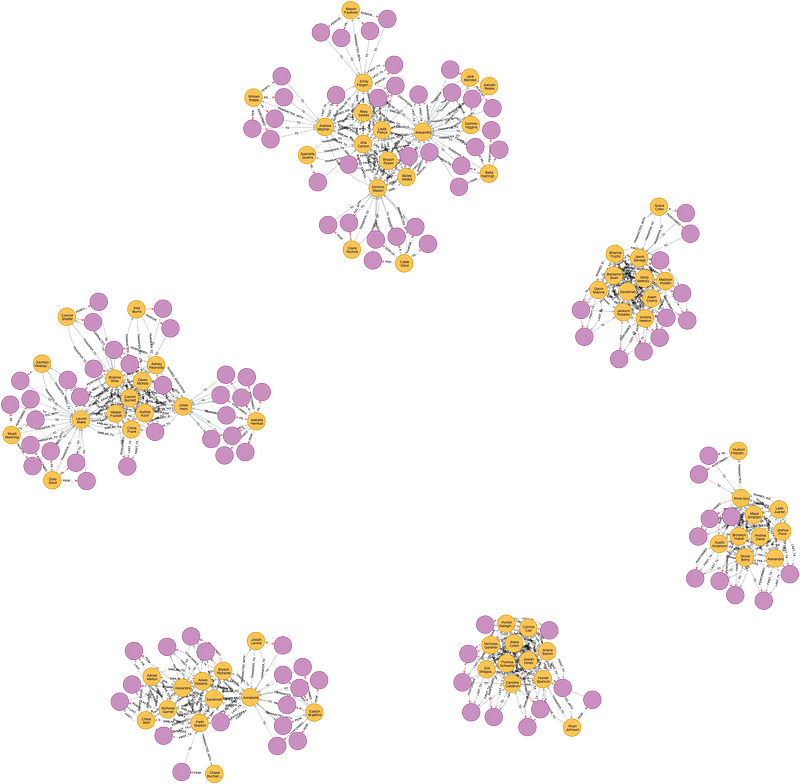
創造新關係
在帶有firstPartyFraudster標籤的客戶和沒有此類標籤但與詐騙者進行交易的客戶之間創建 TRANSFER_TO的關係,並把此類型交易的總金額當作屬性加入TRANSFER_TO
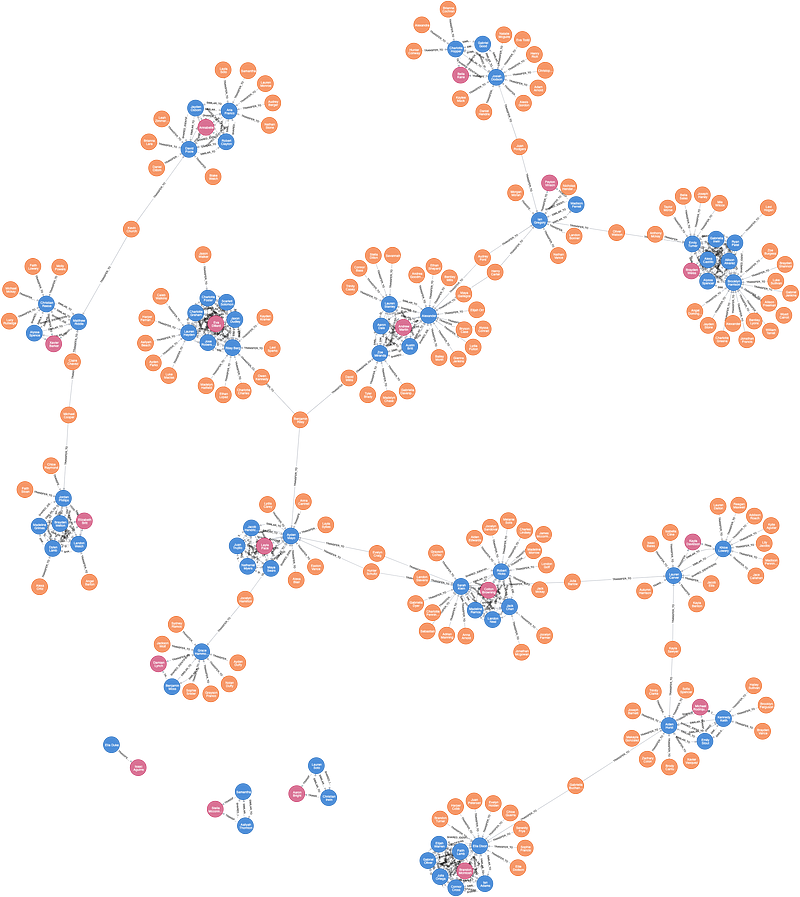
找出 2nd-level Fraudsters
找出可能與第一方詐欺犯勾結的客戶,並沒有被確定為潛在的第一方詐欺犯。
我們的假設是,執行轉帳類型交易(Transfer)的客戶,他們從第一方詐騙犯那裡發送或接受資金,可以被懷疑為 2nd-level Fraudsters
識別這些客戶使用剛剛創建的TRANSFER_TO關係,並執行下面的步驟:
1. 使用社區檢測算法(WCC)來識別與第一方詐騙者有關的客戶網路
2. 使用中心性算法(Page Rank)計算一個Fraud Score(風險評分)
3. 找出相對Page Rank高的嫌疑犯,並標記為2nd-level Fraudsters
1. 使用WCC找出與第一方詐騙者有關的客戶網路

2. 使用中心性計算影響力分數
使用Page Rank算法計算中心性分數,以找出嫌疑人中誰的Page Rank分數相對高的

3. 找出相對Page Rank高的嫌疑犯,並標記為2nd-level Fraudsters
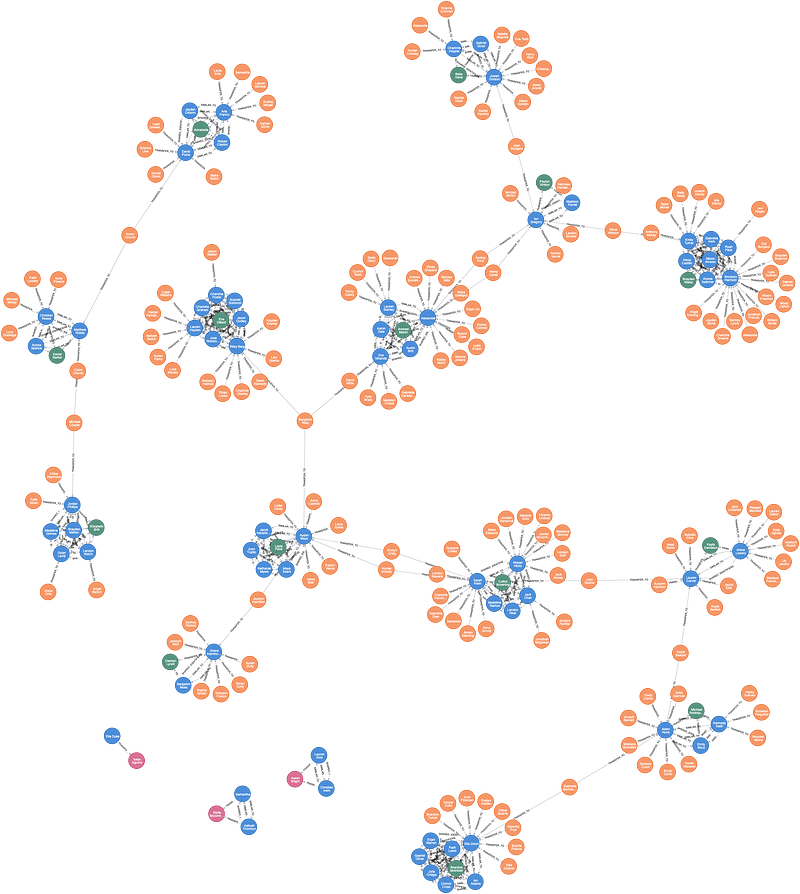
第一部分總結:我們發現了什麼?
綜上所述,我們使用GDS來執行金融交易數據分析中的一些關鍵步驟:
1. 我們使用WCC 與Degree Centrality算法篩出潛在的第一方詐騙犯。
2. 使用新建立的關係(TRANFER_TO),利用WCC與Page Rank算法找出與第一方詐騙犯相關聯的2nd-level Fraudsters。
3. 在原本的網路上標籤這些嫌疑犯
下一章節,會結合Machine learning 來做金融詐欺的預測。
Machine Learning — 詐欺犯預測
此章節會利用GDS 提供的Machine learning 工具,來預測客戶為詐欺犯的機率。
以下步驟為處理流程:
1. 為一些客戶標記是否為詐欺犯
2. 增加更多properties作為features (feature-engineering)
3. 使用 FastRP 作為node embedding
4. Train and Test Model
5. Make prediction
1. 標籤是否為詐欺犯
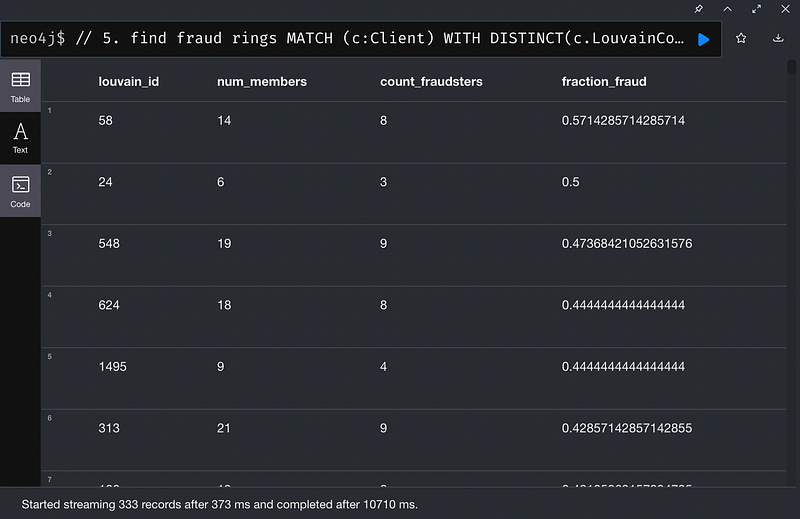
在做機器學習時,我們必須給電腦一些有Label的數據去學習,但因為PaySim並沒有為客戶標示是否為詐欺犯,因此我們假設如果客戶有參與10筆以上詐騙交易,就有很大的概率為詐欺犯,我們把這些客戶標示為詐欺犯。並且把上一章節中我們找出的嫌疑詐欺犯標示為詐欺犯。
另一方面,我們使用Lovain 算法為客戶分群,如果這個客戶群集裡有前面標示的詐欺犯比率小於0.065,把這些客戶標示為無辜者(非詐欺犯)
2. 增加更多的Features
使用GDS裡的Degree、Page Rank、Triangle Count來為節點增加更多的features。

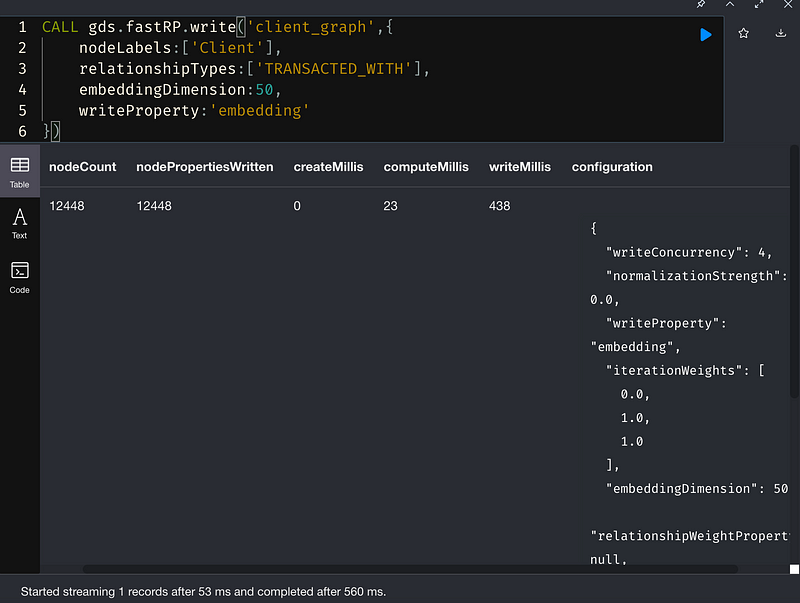
3. 使用FastRP作為node embedding
使用GDS裡的FastRP 進行節點向量化,把節點跟節點之間的關聯向量化加入節點特徵中。
Node Embedding(節點嵌入)算法計算圖中節點的低維向量表示。這些向量,也被稱為嵌入,可用於機器學習。
快速隨機投影(Fast Random Projection, or FastRP)是隨機投影算法族中的一種節點嵌入算法。可以將n個任意維數的向量投影到O(log(n))維數中,並且仍然地保持節點之間的成對距離。
更多訊息參考:Fast Random Projection — Neo4j Graph Data Science
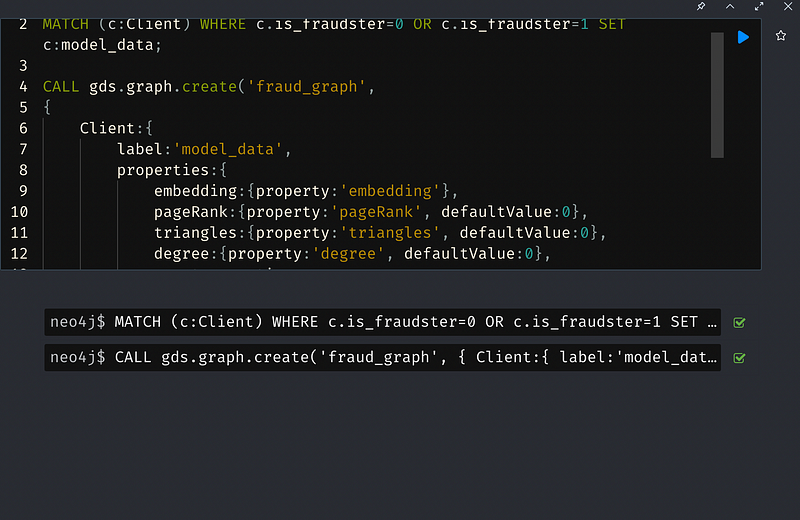
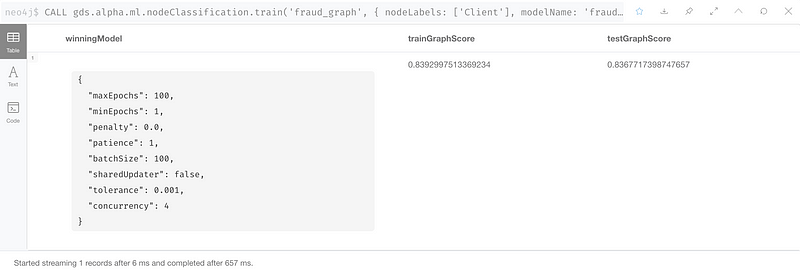
4. Train and Test Model
這個步驟為創建我們的預測Model並且訓練這個Model,隨後測試Model準確度。
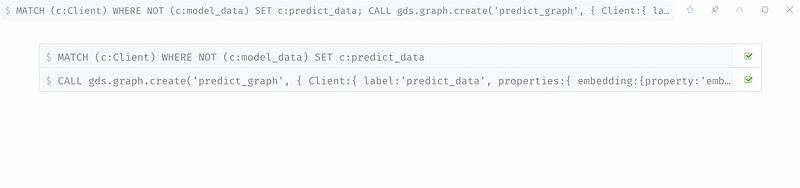
5. Make Prediction
這個步驟,標籤前面我們沒標籤的Client,用剛剛訓練好的模型來預測這些Client是否為詐欺犯的機率。
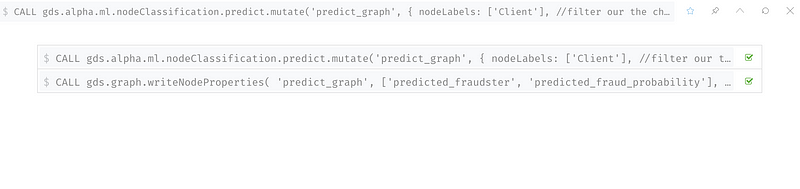
第二部分總結:我們做了什麼?
綜上所述,我們使用GDS來建立模型與預測客戶是否為詐騙犯的機率的一些步驟:
1. 建立部分客戶Label為詐欺犯或非詐欺犯,藉由使用Lovain算法來計算
2. Feature Engineer (使用GDS裡的Degree、Page Rank、Triangle Count來為節點增加更多的features。)
3. Node Embedding- FastRP算法
4. Train and Test Model
5. 利用訓練好的模型,預測圖中未標籤的客戶