Session 管理技巧
前言
我們都知道任何 AI 工具都有 context limitation,即一次「對話」可以儲存的記憶上限,如果對話累積超過上限,就會讓 AI「忘記」一些指令,導致記憶錯亂。屬於 AI 幻覺 (Hallucination) 的一種。
例如:開始回答一些已經判定為結案的話題、把過去岔題的內容偷渡進正在討論的主題⋯⋯等等,看起來好像對,但不完全是我們想要的內容。
現在各大廠商的最直接的解決辦法叫做 context compression,即,在 context window 快滿時 AI 拿來壓縮對話的機制,但 compression 不是真正的問題來源。
這個現象早在對話壓縮功能推出之前就有了,名為 Dumb Zone:當上下文的 token 數量達到某個上限之後,模型的輸出品質就會急劇下滑。*
對話壓縮做到的事只有「延長對話」,這個功能對產出的品質不會有任何改善,我們只能從他似懂非懂的回答延續這個錯誤螺旋。
解決這個問題的辦法其實很簡單:早在 session 被污染之前,先把這個對話的「核心目的」萃取出來放到 md 裡面。
用 LLM 的角度來看,這個對話從開始到結束都是「核心目的」,他也是會基於對話中的指令迭代出新的回饋,所以下面兩句話的權重對模型來說完全相同:
- 「你現在是一位在金融領域工作十年的資深軟體工程師」
- 「為什麼這要寫在前端」
如果我們想要讓這個 session 每次的回覆都是以「資深軟體工程師」角度出發,就要特別把這件事情定下來。
「這不就是 predefined / prompt instructions 嗎?」
正是 Claude 的 CLAUDE.md——也可以說是 Copilot 的 .github/prompt,或是 Amazon Kiro 的 Steering files。都是相同概念,坐在 session 外面,不管 session 中發生什麼事情都不會受到影響。這些大廠很早就發現這個現象,讓 Markdown 文件成為整個對話的錨點 (Anchor),為方便說明暫先稱作 錨 Anchor。
Static V.S. Evolving
以 CLAUDE.md 來說,裡面大概會定義以下:
- 程式風格 & 命名規則
repo的協作慣例- 個人化要求,諸如:只要修改超過三個檔案就開一個
branch、什麼功能限定哪個版本測試、git規則⋯⋯等等
將原則錨定之後,不論 session 壓縮幾次,對話都會參照這份 markdown 持續運作。
但是我們都知道,沒有不會改變的需求。所以「錨」也要跟著動、要跟著專案進化 (evolve)。每當設計語言改變、欄位調整、法規更新⋯⋯等等,就更新回 md。這麼作一定可以讓每次的 session 都更加精練。
至於什麼時候要更新 md,有以下幾種時機點:
- 需求明確的變更
- 在
Git / Branch的時候,讓 md 進入版控前(比較不會忘記) - Context Canary 上下文金絲雀測試 **
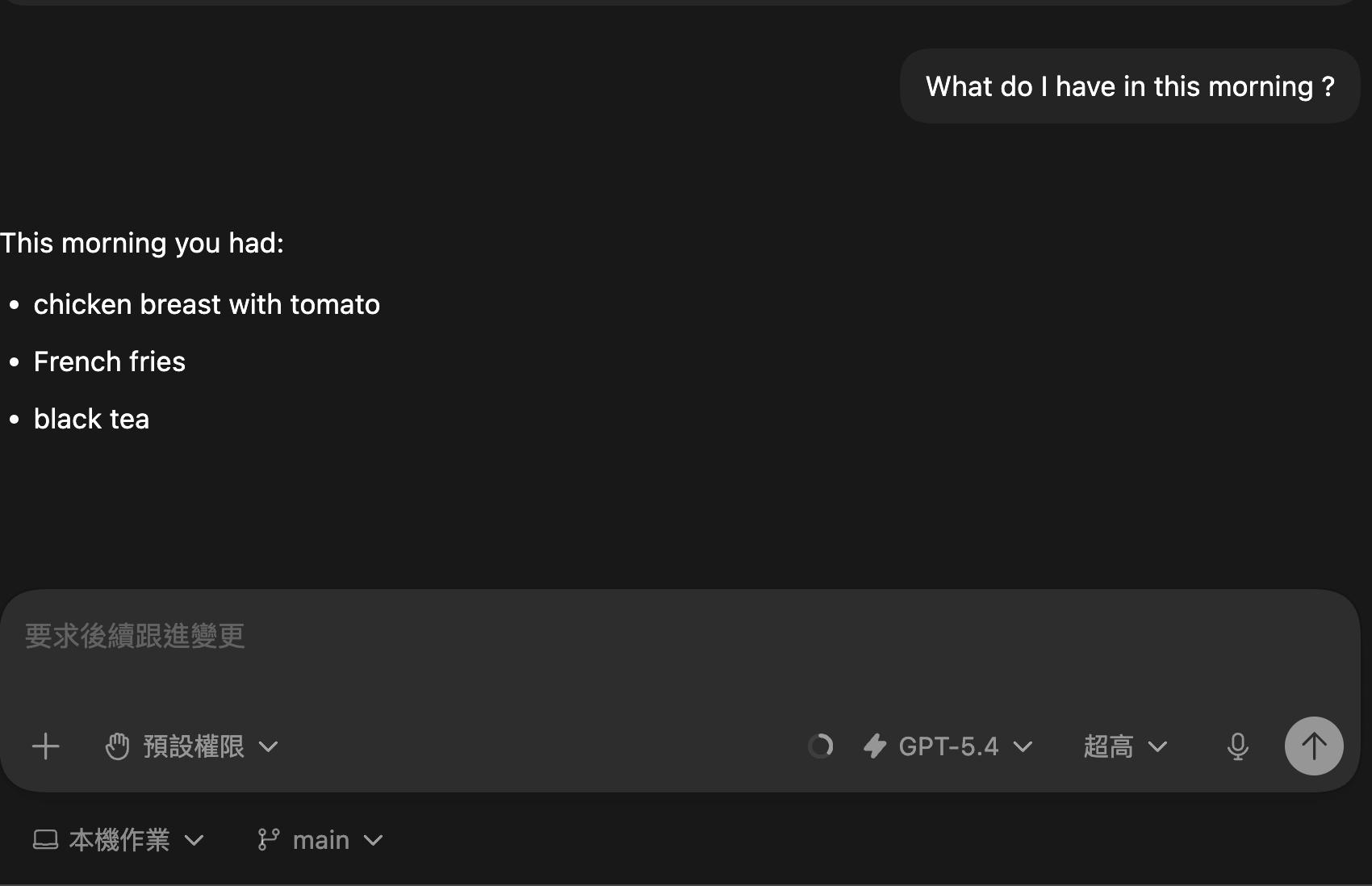
session開頭埋一個和工作完全無關、但很具體很好驗證的事實,例如:我早上八點吃早餐,早餐是三明治。過程中定期問模型那個事實還記不記得。如果他開始亂答,那就是時候該把session重啟囉(這時候我們已經有 Anchor,別怕!)
為了製造錯誤情境,vibe code 了一個小專案,過程中刻意從 React 轉換成 Angular,並且大改需求,但仍然沒有出現記憶錯亂的情況,應該要慶幸我的使用習慣算良好,希望錯誤情境不會出現在大家實作的時候(苦笑)
At 08:30 this morning, I had breakfast. The meal included chicken breast with tomato, French fries, and black tea.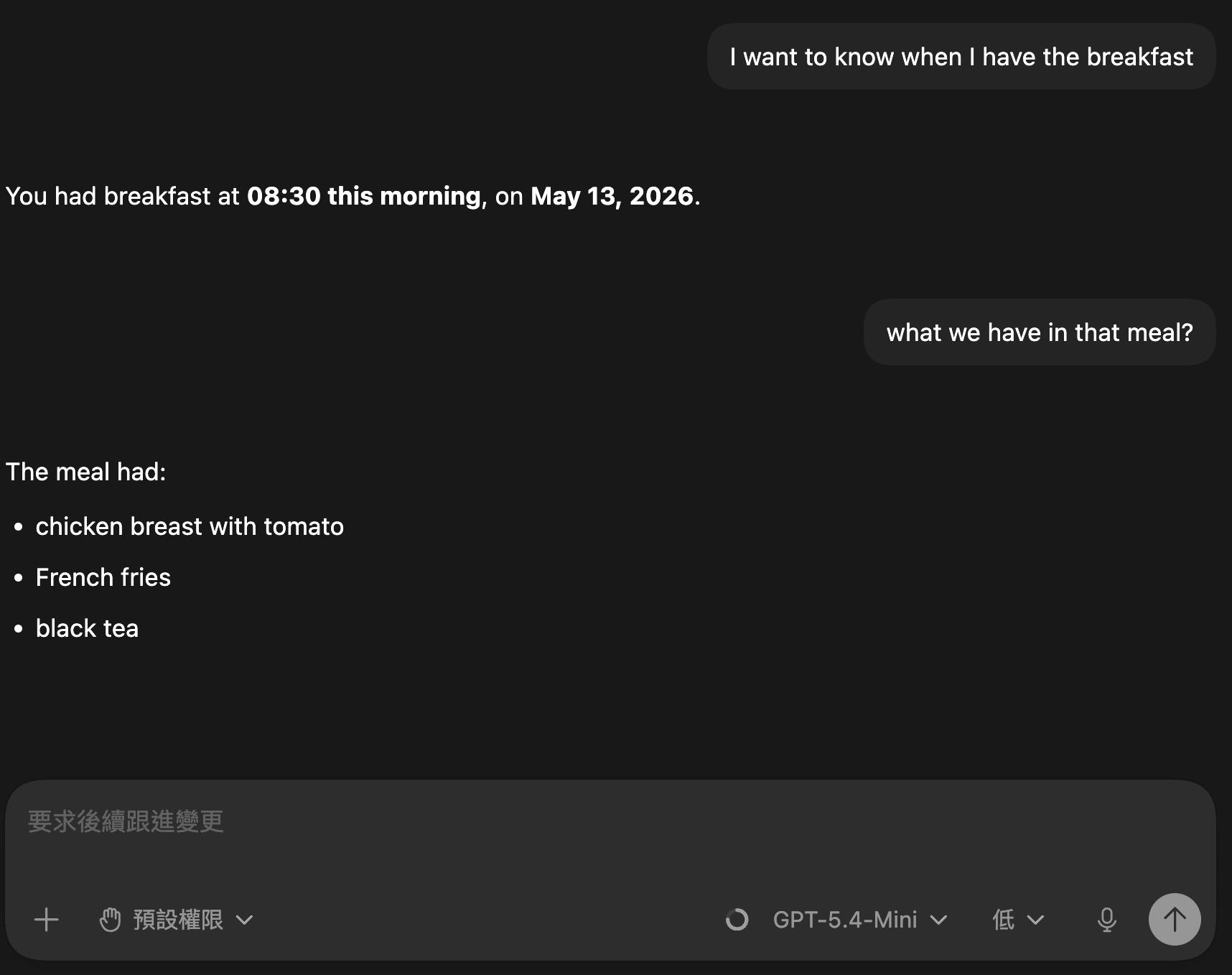
圖中經歷過數次壓縮和模型切換,還是能正確辨識
- Subagent Boundary / Skills
與其在長session裡面管理 md,我們直接把session分割,從源頭治起。最簡單的做法就是:開一個專案資料夾,把會用到的內容放進去,一個session只做一件事,減少幽靈現象發生。
總結
AI 工具很方便,不過使用者還是「人」(我們),這邊引用的技巧都是從系統上進行管理,再聰明的模型都可能會出現狀況。LLM 出錯並不可怕,最恐怖的是他出錯了我們還不曉得!有機會的話試試看上面的技巧吧,若有什麼想要分享的,也可以一起討論。
資料來源
- — 〈We're All Addicted To Claude Code〉 YC Lightcone Podcast
- — 〈Inside Claude Code With Its Creator〉YC Lightcone Podcast
- — 〈Spec-Driven Development: Unpacking one of 2025's key new engineering practices〉
- —
kiro.dev/ AWS docs.Steering files、selective context loading