快速使用Baidu的開源框架Paddle(PArallel Distributed Deep LEarning)作Chinese OCR測試
Introduction
Baidu have developed PaddlePaddle2.0 enging for Optical Character Recognition(OCR), which can be used to detect text and recognize characters in digital images. The traditional chinese model trained by Baidu is released this year, this is a quik start guid help you to use it for converting traditional chinese image to traditional chinese text.
Environmental requirements
+ PaddlePaddle 2.0
+ PaddleOCR repository
+ python 3.7.X
+ shapely
+ scikit-image==0.17.2
+ imgaug==0.4.0
+ pyclipper
+ lmdb
+ opencv-python==4.2.0.32
+ tqdm
+ numpy
+ visualdl
+ python-Levenshtein
* 3rd-party libraries in python are described in requirements.txt of PaddleOCR
Installation
1) Install python 3.7.X (this machine is using 3.7.10) on mac
brew install python@3.7
python --version # check your python version 2) Install PaddlePaddle 2.0
pip3 install --upgrade pipif you only have CPU on the machine, run the command:
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simpleor having GPU:
python3 -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple3) clone PaddleOCR repository from github : https://github.com/PaddlePaddle/PaddleOCR.git
4) Open the project PaddleOCR, install 3rd-party libraries as mentioned previously
pip3 install -r requirements.txtensure the 3rd-party libraries are all installed in python, you can check that by using 'import':
(paddle) jojolinde-MacBook-Pro:systalk-ocr jojolin$ python
Python 3.7.10 (default, Feb 26 2021, 10:16:00)
[Clang 10.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import shapely
>>> enter python shell then type 'import shapely', python returning no error indicate the libray 'shapely' is installed successfully.
To download the inference models trained by Baidu
Let's take the Ultra-lightweight Chinese OCR model ch_ppocr_mobile_v2.0 as an example :
please refer to model list https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_en/models_list_en.md
Link to download the models as below:
inference text detection model
inference text angle classification model
inference text recognition model
download three models and unzip, you will see three files with the same name but different extension such as *.pdiparams, *.pdiparams.info, *.pdmodel, and make sure the file structure should be like:
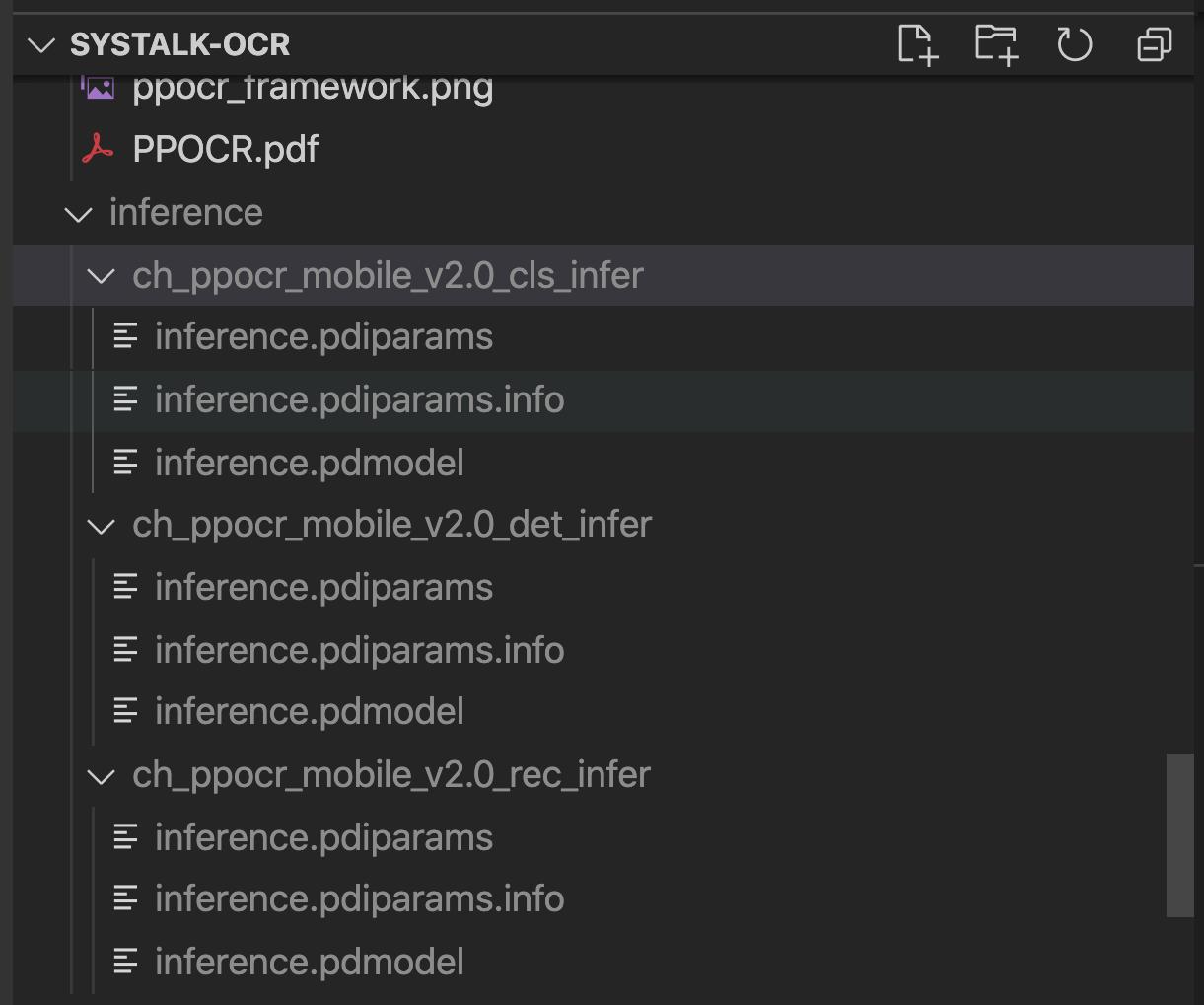
these three models are placed under directory './inference', which for text detection, text angle class and text recognition, respectively.
To provide a test .png image to the model
For now we wanna use traditional chinese model instead of ultra-lightweight Chinese model for traditional chinese charaters recognition, so the parameter --rec_model_dir will be assigned the path of "chinese_cht_mobile_v2.0_rec_infer", and use the angle classification model without GPU.
Also other parameters will be used:
--image_dir: the path of input *.pngrec_char_type: language
--
--rec_char_dict_path: the path of language dictionary
--det_model_dir: the path of text detection model
--cls_model_dir: the path of angle class model
--rec_model_dir: the path of text recognition model
--use_angle_cls: whether to use angle class model
--use_space_char: whether to recognize spaces
--use_gpu: whether to use GPU
Get a image named 'systalk.png' under the directory './test',

then analyze it by the command:
python3 tools/infer/predict_system.py
--image_dir="./test/systalk.png" --rec_char_type="ch_tra" --rec_char_dict_path="./ppocr/utils/dict/ch_tra_dict.txt"
--det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/cht/chinese_cht_mobile_v2.0_rec_infer/"
--cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/"
--use_angle_cls=True --use_space_char=True --use_gpu=FalsePaddle works successfully as the following:
[2021/04/20 14:53:47] root INFO: dt_boxes num : 6, elapse : 0.4800539016723633
[2021/04/20 14:53:47] root INFO: cls num : 6, elapse : 0.07534313201904297
[2021/04/20 14:53:47] root INFO: predict_rec.rec_result=> [('詳細資訊', 0.9674002), ('SYSTALK', 0.993779), ('交談式AI產品', 0.89832836), ('AI理想由我們來實踐!', 0.90451914), ('勒力鮮決方案·簡化企業管理流程·您的', 0.85203815), ('折力A研發團隊寫企業量身打造A數位學', 0.8889663)]
[2021/04/20 14:53:47] root INFO: rec_res num : 6, elapse : 0.24634599685668945
[2021/04/20 14:53:47] root INFO: Predict time of ./test/systalk.png: 0.859s
[2021/04/20 14:53:47] root INFO: SYSTALK, 0.994
[2021/04/20 14:53:47] root INFO: 交談式AI產品, 0.898
[2021/04/20 14:53:47] root INFO: 折力A研發團隊寫企業量身打造A數位學, 0.889
[2021/04/20 14:53:47] root INFO: 勒力鮮決方案·簡化企業管理流程·您的, 0.852
[2021/04/20 14:53:47] root INFO: AI理想由我們來實踐!, 0.905
[2021/04/20 14:53:47] root INFO: 詳細資訊, 0.967
[2021/04/20 14:53:47] root INFO: The visualized image saved in ./inference_results/systalk.pngDisplay total number '6' of text lines, every text line and its score, and elapsed time. the result of characters recognition is not perfect, maybe we could try to retrain the inference model with more trainning samples. The visualized image only displays sentences with score >= 0.5(by default) and is saved to the folder './inference_results' by default, it looks like:

Reference
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_en/installation_en.md
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_en/models_list_en.md
edited by jojolin