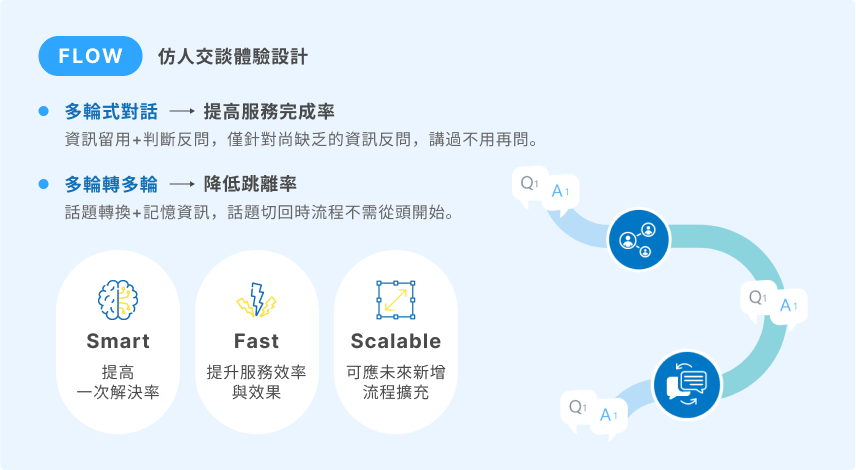
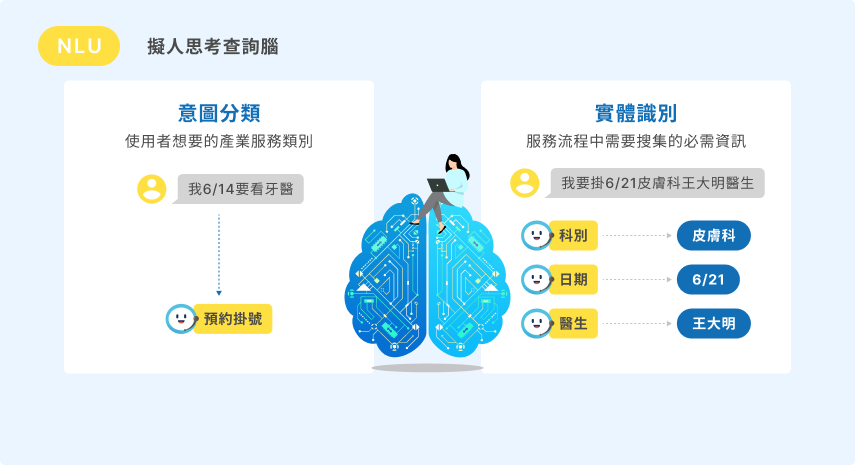
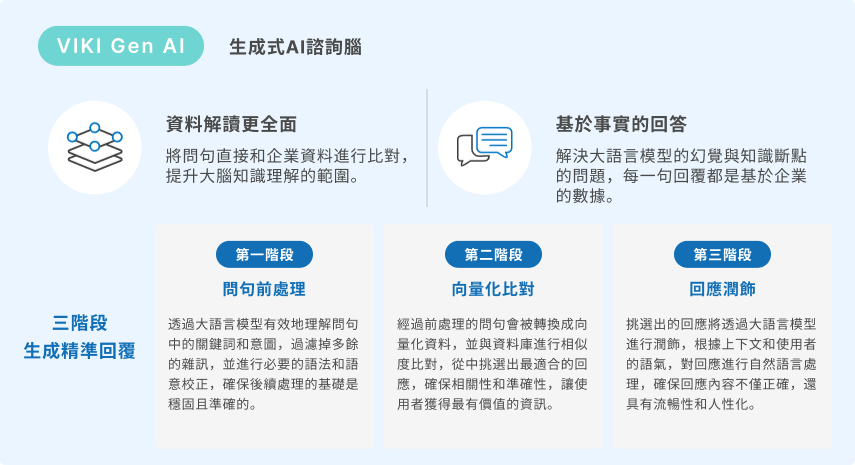
串接雙腦與系統API建立交談流程,並有「多輪對話」及「多輪轉多輪對話」設計,貼近真人對話習慣,建立仿人交談體驗。






















SysTalk.ai 具有專門導入服務團隊,擅長協助企業進行大量語料解析、分類,並且規劃業務流程,協助進行建置 AI 大腦。團隊成員包含專案管理師、語言訓練師、流程規劃工程師等等。 協助您完整完成 SysTalk.Chat 專案。




YouBike 小管家 AI 客服透過 SysTalk.Chat 在官方網站、官方App 等渠道建立完整且最擬人的客服問答機制,全天候輔助真人客服服務廣大的用戶群,包含了場站資訊、租借狀態、失物招領、通報協尋等項目,提供24小時不間斷的線上資訊服務。

昕力團隊協助信義房屋建置找房助理,使用手機內建Google助理即可喚醒,運用NLU自然語言理解技術,讓使用者用不同的問法,皆可辨識出服務的意圖,提供民眾個人化智慧找房、查詢實價登錄服務。

昕力團隊協助Wemo Scooter打造智能客服威威,於App提供24小時諮詢服務,可即時回答操作使用、保險車禍相關、騎乘注意事項,並提供方案介紹服務,讓使用者不論是否在客服上班時間,都能完整獲得資訊,輕鬆上手租用服務。






