MongoDB的儲存限制
主題: |
MongoDB的儲存限制 |
文章簡介: |
說明MongoDB的儲存限制,與一旦超過MongoDB儲存限制時的處理方式說明。 |
作者: |
夏宏彰 |
版本/產出日期: |
V1.0/2016.7.14 |
5. MongoDB Memory Limit – 32TB
1. 前言
• 本文件用來提供MongoDB或WingDB的操作人員如何處理當MongoDB超過儲存容量限制時發生的狀況。
• 使用MongoDB 2.6.6 Linux (64bit)進行說明。
其他相關名詞:
• Replica Set: MongoDB的複製集,可以達到資料的非同步抄寫與錯誤回復的需求。
• Shard Cluster: 分割叢集,可以將大量的資料分割到多個MongoDB,達到橫向擴充的目的。
2. 目的
• 了解MongoDB的儲存限制。
• 處理MongoDB Out Of Memory的狀況。
3. 開始前準備
本說明基於以下版本的環境:
• MongoDB 2.6.6 (64bit)
• RedHat 7
提供對象:
• 對MongoDB的資料儲存有初步的了解
• 了解MongoDB Replica Set的運作
• 了解MongoDB Shard Cluster的運作
4. MongoDB Memory使用方式
常有人遇到MongoDB用了大量的Memory甚至將系統的Memory吃光了,所以他想要限制MongoDB使用Memory的大小。但實際上是無法限制的,也不要想用其他方法限制,這與MongoDB儲存檔案所用的格式有關,且一但限制,則他限制的就是你的資料量。
MongoDB是用Memory-Mapped Files的格式存放資料,Memory-Mapped File 是作業系統透過mmap()存放memory資料用的檔案。也就是說mmap()將檔案對映到系統virtual memory的一個區域,資料檔案由記憶體載入與移出是由Linux管理的,而是否進行快取、快取的大小為何,同樣由Linux所決定。當我們在Linux上透過top觀看mongod的processes時我們會發現其實MongoDB所用的實體記憶體(RES)的部分並不大,但它所使用的虛擬記憶體(VIRT)就相當驚人,這就是MongoDB用Virtual Memory記錄資料的說明。所以我們不可以也不能去限制MongoDB使用記憶體的大小,尤其是virtual memory更要設定成unlimited,若你的資料量很大的話,限制virtual memory就等於是限制你存放的資料量。
那麼MongoDB還會用到Linux系統的Swap嗎? data的部分不會,由上述說明可知data的部分本身就是virtual memory了,但其他如連線的部分還是有可能用到。Client對MongoDB的連線每一條約用1MB的記憶體,基本上是不太可能用到1GB以上的記憶體,但為了避免Linux發生oom-killer錯誤,或是系統上同時也有其他應用執行,建議還是要設定以維持系統的穩定度。
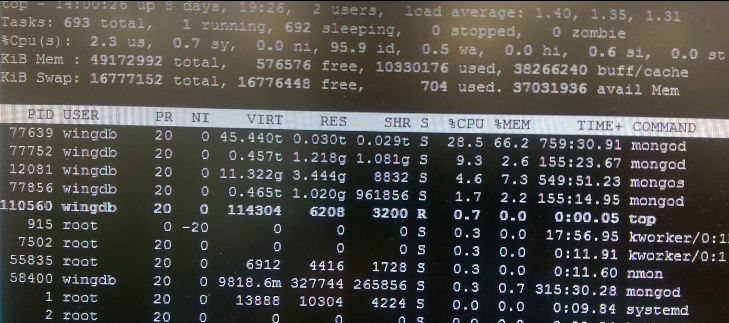
下圖是實際top的一個例子,以第一個mongod而言虛擬記憶體有45.44TB,但實體記憶體用量僅有約30GB。
>top
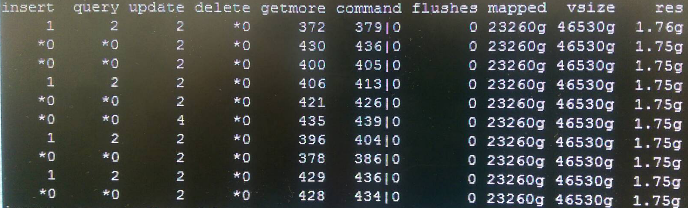
下圖是同一個mongod的mongostat的例子,我們看到vsize有46530g,這與top看到的45.44T是一致的。而res僅有1.76g,這似乎與top看到的有相當的落差,應該是計算的方式不同吧! 再看到mapped,此即所謂Memory-Mapped的大小,是實際MongoDB所存資料的大小,vsize約是mapped的兩倍大。
> mongostat
5. MongoDB Memory Limit – 32TB
什麼? MongoDB 64bit有儲存資料大小的限制!
是的,MongoDB使用Virtual Memory記錄資料,所以底層OS的virtual memory address space的極限就是MongoDB所能記錄資料大小的極限。但64bit很大吧,是Long資料的最大值吔! 應該很難超過才是。但實際上64bit作業系統的空間限制並非2^64 (1.8EB)這麼大,以RedHat而言,不同版本的64bit也不同,如下表所示:

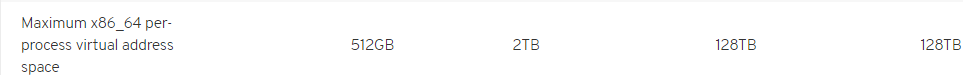
(參考: https://access.redhat.com/articles/rhel-limits)
但MongoDB的資料大小限制是128TB嗎? 再來看下表:
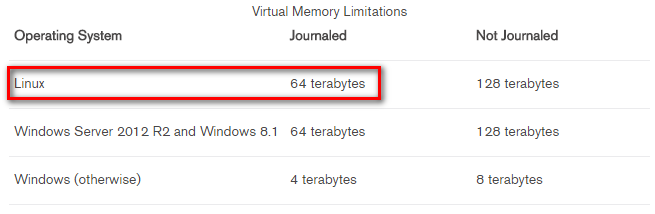
(參考: https://docs.mongodb.com/v2.6/reference/limits/#data)
沒錯,virtual memory的限制當Not Journaled是128TB,但若有使用Journal則只剩一半64TB,而memory mapped的大小是virtual memory的一半,所以就僅有32TB可用。換算成MongoDB的data files數量約為16000個,一個2GB計算下來也剛好是32TB。
6. 超過32TB會發生什麼事?
32TB的確沒有那麼容易超過,就算要超過一般也是好幾個月以後的事,也可能是好幾年後。我們要先預估系統資料可能的成長,可一開始就規劃成Shard Cluster,或是等資料確實達到某一個值時再來擴充。
以MongoDB能夠將現行standalone轉換成shard的限制來看,若一開始就預估資料會成長200G以上時,建議一開始就規劃成Shard Cluster,否則就不用,畢竟Shard Cluster的建制成本與複雜度比Replica Set多了好幾倍。
再回來看,單台MnogoDB用超過32TB時資料將無法再寫入,Java Client出現的錯誤大概如下:
• "code" : 12520 - "new file allocation failure"
• "code" : 14031 - "Can't take a write lock while out of disk space"
com.mongodb.WriteConcernException: { "serverUsed" : "localhost" , "ok" : 1 , "n" : 0 , "err" : "new file allocation failure" , "code" : 12520}
at com.mongodb.CommandResult.getWriteException(CommandResult.java:90)
at com.mongodb.CommandResult.getException(CommandResult.java:79)
at com.mongodb.DBCollectionImpl.translateBulkWriteException(DBCollectionImpl.java:316)
…
com.mongodb.WriteConcernException: { "serverUsed" : "localhost:28001" , "ok" : 1 , "n" : 0 , "err" : "Can't take a write lock while out of disk space" , "code" : 14031}
at com.mongodb.CommandResult.getWriteException(CommandResult.java:90)
at com.mongodb.CommandResult.getException(CommandResult.java:79)
at com.mongodb.DBCollectionImpl.translateBulkWriteException(DBCollectionImpl.java:316)
MongoDB Server端出現的錯誤如下:
• errno:12 Can not allocate memory
• ERROR: mmap failed with out of memory. (64 bit build)
• Assertion: mmf.opne failed
• 13636 ”open/create failed in createPrivateMap” //執行show dbs時
2016-06-15T13:13:16.974+0800 [conn13432] ERROR: mmap() failed for /data/MYDB.5019 len:2146435072 errno:12 Can not allocate memory
2016-06-15T13:13:16.974+0800 [conn13432] ERROR: mmap failed with out of memory. (64 bit build)
出錯的Database(一MongoDB可建立多個Database)亦無法讀取資料,但其他非出錯的Database仍可讀取資料(findOne())。查詢時出現錯誤如下:
• 13636 ”open/create failed in createPrivateMap”
7. 問題解決
另建DB儲存過多的資料; 若原本是Shard Cluster,則新增Shard以擴充資料空間。已出錯的Database只能刪除,看來是無法將資料復原了。為了預防此問題再度發生,可另外設一監控機制,例如當Memory Mapped超過20TB,或是Virtual Memory超過40TB時則要準備新增一個Shard,適當的設定Shard Key。
刪除Sharded Database (ex. MYDB)要注意的問題:
• 刪除要先將Balancer停止
• sh.stopBalancer();
• 否則Balancer做到一半的問題會在重建相同DB Name後出現moveChunk fail問題。
• 刪除失敗,顯示Device busy
• 這可能是各Database單獨mount進來的volume無法真正刪除所造成的錯誤訊息,一般可以乎略。
• 可直接到各個instance的dataPath將該目錄清空(MYDB>rm -fr *)。
• 若是用link方式建立目錄,則需重新連結:
• localhost>ln -s /storage/MYDB ./MYDB
• 刪除正常,但show dbs仍存在該DB name,或是顯示(empty)
• 這大部分是因為各shard的Database沒有真正刪除乾淨,可由各shard的Primary進入再刪除,或是直接到各個instance的dataPath將該目錄清空(MYDB>rm -fr *)
• 將configServer上舊DB的配置資料手動刪除乾淨
• mongos>use config
• mongos>db.chunks.remove({“ns”:/^MYDB.*/});
• mongos>db.collections.remove({“_id”:/^MYDB.*/});
• mongos>db.tags.remove({“ns”:/^MYDB.*/});
• 重啟Balancer
• sh.startBalancer();
• 可重新建立失敗的MYDB了!
• 先準備好一組Replica Set
• 加入Shard Cluster
• 若有Shard Tags再指定適當的Tags給新的Shard
重建Sharded Database (ex. MYDB)要注意的問題:
• moveChunk fail
• 由於刪除MYDB時未先將Balancer停止,造成原作業一直在等待lock,無法將新建的Sharded Database的Shard Collection的chunks依我們指定的tags正確的移到相對應的shard。
• 解決方式:
• 例如chunks無法移到Shard001,則表示Shard001有等待lock的狀況,可將Shard001的Primary setpDown(),則在該Primary等待lock的作業會立即停止。
• 在mongos的log確認moveChunk問題不再發生。
• 3 ~ 5min後,sh.status()查看chunks已移到Shard001上。
• 完成。
8. 參考:
What are memory mapped files?
https://docs.mongodb.com/v2.6/faq/storage/#what-are-memory-mapped-files
Do I need to configure swap space?
https://docs.mongodb.com/v2.6/faq/diagnostics/#memory-diagnostics
How do I calculate how much RAM I need for my application?
Red Hat Enterprise Linux technology capabilities and limits
https://access.redhat.com/articles/rhel-limits
MongoDB Limits and Thresholds - Data
https://docs.mongodb.com/v2.6/reference/limits/#data
MongoDb DropDatabase Not Working
http://stackoverflow.com/questions/9407838/mongodb-dropdatabase-not-working
moveChunk failed to engage TO-shard in the data transfer